
When working with an OLTP database, customers’ data protection concerns manifest in different ways. Whether it is about the ability to encrypt data with one’s own keys, redacting cluster logs, field-level data masking or something else, we have partnered closely with our customers in providing more than what they were looking for.
So, when we heard feedback that customers needed a way to obfuscate cloud resource credentials when running backup-restore or changefeed SQL commands, we decided to outdo that requirement.
Backup-Restore and real-time changefeeds are two of the most critical capabilities in an OLTP database. The former applies to disaster recovery whereas the latter allows integration with analytics platforms or is sometimes used for replication.
When it comes to cloud-native databases like CockroachDB, the sinks or target resources for both those capabilities are typically cloud storage or streaming services (Backup, Changefeed). Until now, we required users to pass AWS access keys or GCP service account credentials when running those operations on AWS or GCP resources respectively. That meant the users running those operations could access the cloud resources directly if they wanted to, which could become a potential data exfiltration threat vector. Customers could use third-party secret management tools to hide the credentials, but that added another thing to the tech stack, and it is still not a foolproof solution.
We’ve gone above and beyond the ask to allow obfuscating cloud resource credentials. It gives us immense pleasure to announce that starting with CockroachDB 22.2, CockroachDB users can use Cloud IAM roles to access their cloud resources for disaster recovery and changefeed operations. With this, we’ve completely eliminated the need to use any cloud resource credentials in relevant SQL commands. Cloud admins can simply create a cloud IAM role with necessary permissions on their cloud resource, trust a CockroachDB identity to access that role, and then share the role name with their SQL users. No more trying to find fancy mechanisms to hide those cloud credentials.
Why use Cloud IAM roles to run backups and changefeeds?
When it comes to taking backups to their managed cloud storage or sending changefeeds to their managed cloud storage or streaming services, we hear following questions from CockroachDB customers:
Is there a way to hide or obfuscate cloud resource credentials when our operators run backup / restore SQL commands?
Could we not have to share cloud resource credentials with our developers to configure their changefeeds to cloud storage?
Do you support short-lived credentials to access cloud resources? If yes, how could that work for long duration full cluster backups or continuously running changefeeds?
Cloud IAM role based access addresses all of the above requirements with CockroachDB (both cloud and self-hosted).
How does Cloud IAM role based access work?
The idea is to enable a workflow similar to how Cloud or DevSecOps admins at an organization enable their Engineering teams to use cloud resources for any other purpose. The mechanism allows cloud admins to create the desired cloud storage or streaming resource plus an IAM role with relevant permissions to read / write to that resource, and share that with the Application Engineering or Database Platform team. Those latter teams could then run backup-restore or changefeed operations using the IAM role(s) as and when needed.
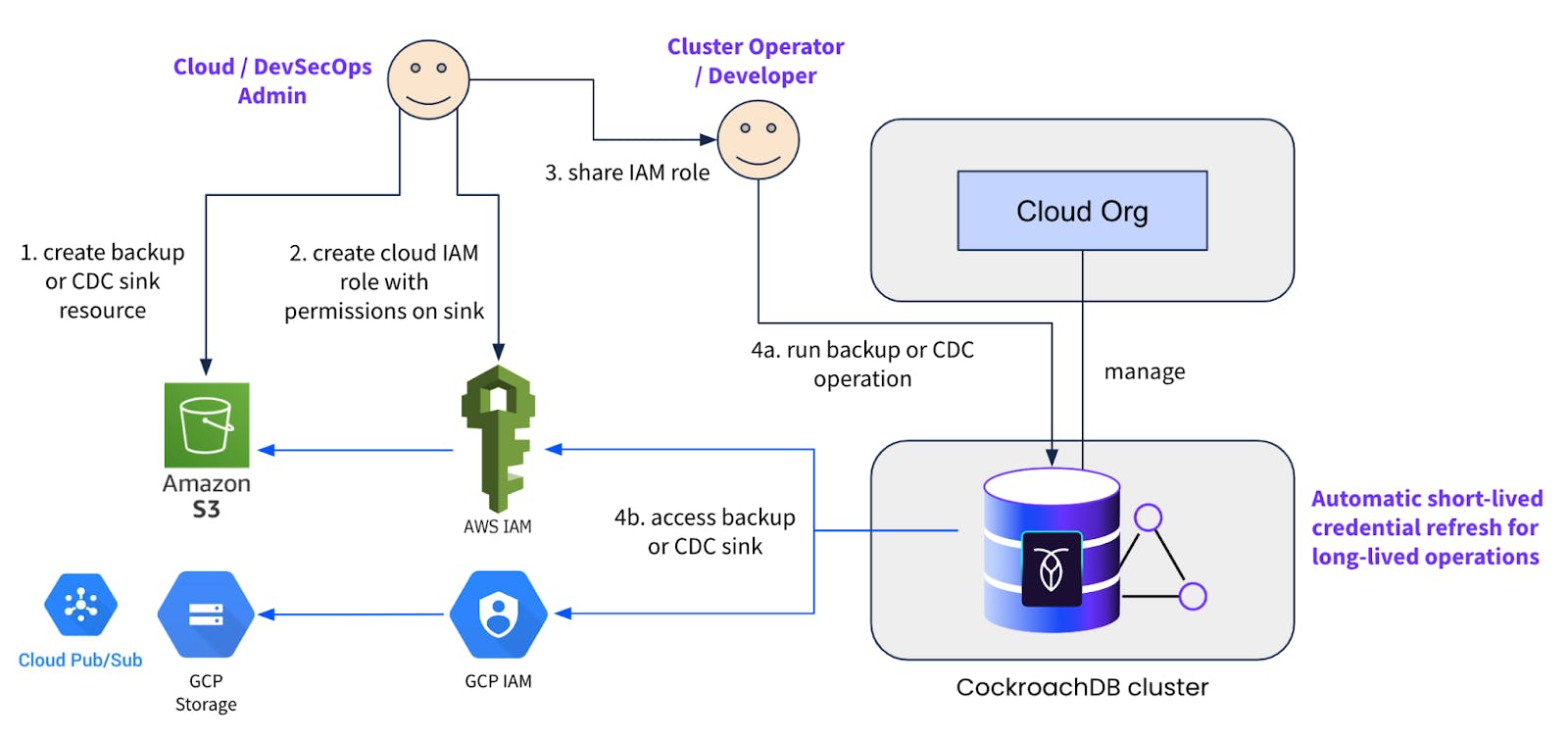
This functionality is available on both CockroachDB Dedicated and self-hosted clusters. When self-hosting, we recommend configuring IAM roles for EKS service accounts or GKE Workload Identity on your cluster nodes if you’ve deployed it on cloud provider managed kubernetes. Those cluster identities should then be configured as trusted identities in the user-provided cloud IAM roles. This is the ideal pattern to avoid configuring any hard coded cloud resource credentials in the cluster nodes for implicit authentication.
On a self-hosted cluster, a backup command using AWS IAM role with access to a S3 bucket would look something like this:
BACKUP DATABASE {database} INTO 's3://{bucket_name}/{path}?
AUTH=implicit&ASSUME_ROLE=arn:aws:iam::{your_aws_account_id}:role/{iam_role_name}';And similarly a command to start a changefeed on a table would look something like this:
CREATE CHANGEFEED FOR TABLE {table} INTO 's3://{bucket_name}/{path}?
AUTH=implicit&ASSUME_ROLE=arn:aws:iam::{your_aws_account_id}:role/{iam_role_name}' with updated, resolved;When it comes to CockroachDB Dedicated, we pre-configure the above-mentioned IAM roles for EKS service accounts or GKE workload identity as cluster identities on our managed clusters. Plus we also add a unique functional IAM role per cluster, which should be configured as a trusted identity on your end in the user-provided cloud IAM roles. We employ a cloud role chaining mechanism such that the cluster identities assume or delegate to the functional IAM role, which in turn assumes or delegates to the user-provided roles. Refer to the diagram below.
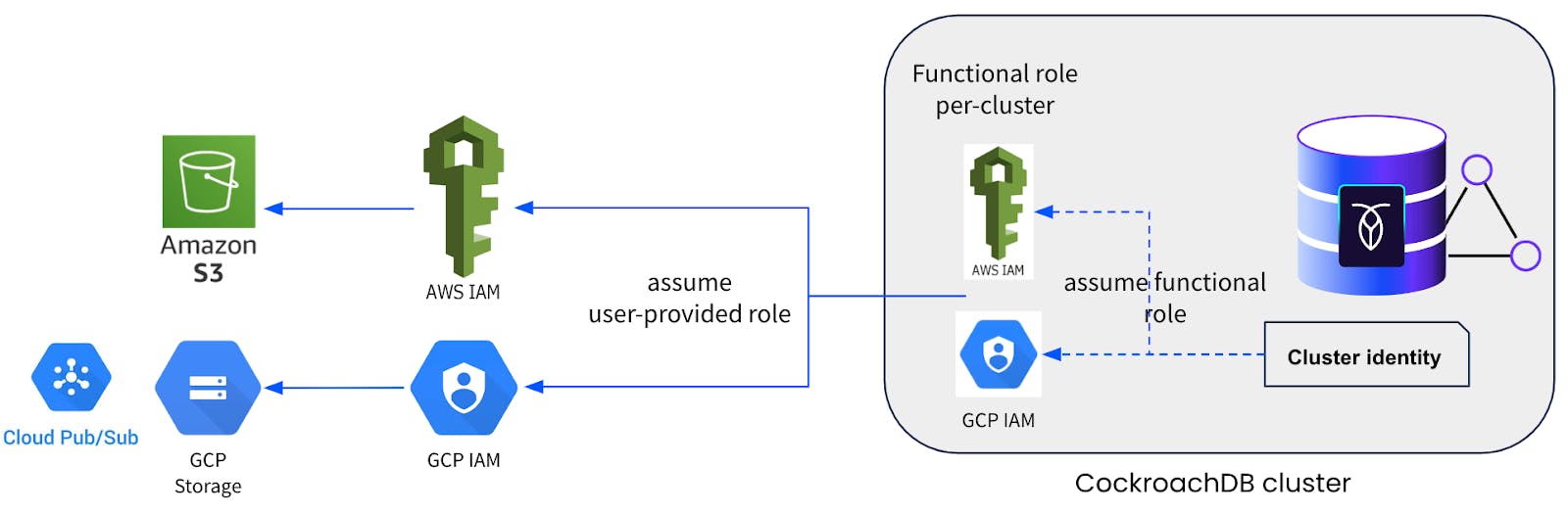
So on a dedicated cluster, the backup command described above would change slightly to accommodate for the functional IAM role:
BACKUP DATABASE {database} INTO 's3://{bucket_name}/{path}?
AUTH=implicit&ASSUME_ROLE=arn:aws:iam::{cluster_aws_account_id}:role/crl-dr-store-user-{cluster_id},arn:aws:iam::{your_aws_account_id}:role/{iam_role_name}';And changefeed command on a dedicated cluster would look something like:
BACKUP DATABASE {database} INTO 's3://{bucket_name}/{path}?
AUTH=implicit&ASSUME_ROLE=arn:aws:iam::{cluster_aws_account_id}:role/crl-cdc-sink-user-{cluster_id},arn:aws:iam::{your_aws_account_id}:role/{iam_role_name}';
The neat thing with using Cloud IAM roles is that the `assume role` or delegation mechanism uses short-lived credentials to accomplish the intended purpose. This avoids having to configure any sort of long-lived credentials for backup-restore or changefeed operations. For long-duration full cluster backups or continuous running changefeeds, CockroachDB automatically refreshes the short-lived credentials under the hood, without requiring the operation to be paused or any user action to be performed.
We now have an elegant solution to a very hairy problem.
How to get started
If you don’t have a CockroachDB cluster yet, get started by creating one by following these instructions for CockroachDB Dedicated or these ones for Self-hosted CockroachDB. Once the cluster is set up, refer to these instructions to use Cloud IAM roles for backup-restore and changefeeds.
Make sure that the user-provided roles trust the cluster identities or functional IAM role for the `assume role` or delegation to work properly.


