

When we think of critical data, we often think of payments, health records, identities, etc. However, when it comes to the functionality of business-critical applications, metadata is often the unsung hero.
This is becoming even more true in the AI era where organizations are using metadata to turn raw data into strategic assets that fuel sustainable and scalable growth. Metadata provides the context behind AI workloads so that developer teams know where it came from, how it’s been used, and whether or not it's trustworthy.
So what happens when you can’t get access to that metadata? Or even worse, when that data becomes unusable? In this post, we will take a look at the importance of always-on metadata, how outages/downtime can impact business operations, and strategies to build a foundation that delivers always-on access to metadata.
Who needs metadata? 
Every business generates metadata and many rely on it whether they realize it or not. Some organizations, especially SaaS providers and AI companies, go further by actively leveraging metadata to create value.
They depend on it for things like:
Connectivity and integrations
User and service configuration
Account and subscription settings
Media and content locations
Data classification and access control
Guardrails for security and compliance
Adding structure to unstructured data
And metadata isn’t just for technical teams. It can underpin the work of nearly everyone (and thing) within an organization. For example:
End users to interact with products seamlessly
Applications to operate correctly and efficiently
System operators to manage performance and uptime
Business owners to ensure governance and compliance
Decision makers to gain insights and drive strategy
There’s a lot of dependencies on metadata because it acts as the control layer for how data, systems, and applications function. If metadata is unavailable, the data itself may exist, but it becomes unusable and unreliable.
What happens to metadata during an outage?
Outages happen for a variety of reasons: network failures, zone outage, regional outage, disk failures, network partitions, and so on. The more complex and interconnected the system, the more opportunities there are for failure.
Unfortunately, outages are extremely common. Our State of Resilience Report found that on average, organizations experience 86 outages each year and the average length of an outage was 196 minutes. During an outage, losing access to metadata means losing the ability to use, control, and trust data.
After an outage, organizations will often analyze the damage and determine the Recovery Point Objective (RPO) and Recovery Time Objective (RTO). These two metrics represent how much data was lost and how long your transactional system was unavailable.
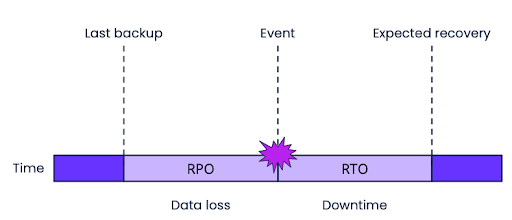
Simply put, a high RPO and RTO is bad for business. It can cost a lot in monetary value, but also in terms of brand reputation. While we often think of unplanned outages as a worst-case-scenario, any amount of downtime can significantly impact business operations.
For example, if you are using a legacy database solution, you might have to take the database offline for routine maintenance. This may include schema changes, upgrades, rebalancing, adding/removing indexes, backups, etc. This might be for a couple minutes, but also could be for a couple of hours. During this time, your metadata is inaccessible.
How can I prevent downtime?
A proven solution for preventing downtime is using a database foundation that has built-in resilience, and delivers online maintenance operations. Let’s take a look at how CockroachDB solves for both.
Because CockroachDB automatically replicates data and spreads it across different Availability Zones (AZs), even when there is a failure, that data is available in another location. This means that CockroachDB can deliver both 0 RPO and near 0 RTO.
[RELATED: RPO and RTO: getting to zero downtime and zero data loss]
Now if you are running a global business, CockroachDB can scale out across multiple regions to deliver global ability for your data. Data is replicated in other regions, and if you modify data in one location, the other regions have the same consistent view.
Running a multi-region deployment greatly helps with availability, but also helps reduce end user latency because CockroachDB allows you to pin data to specific locations for fast access. Additionally, it can aid with meeting regulatory compliance because data is never leaving the designated location.
[RELATED: Metadata management reference architecture: A quick guide with diagrams]
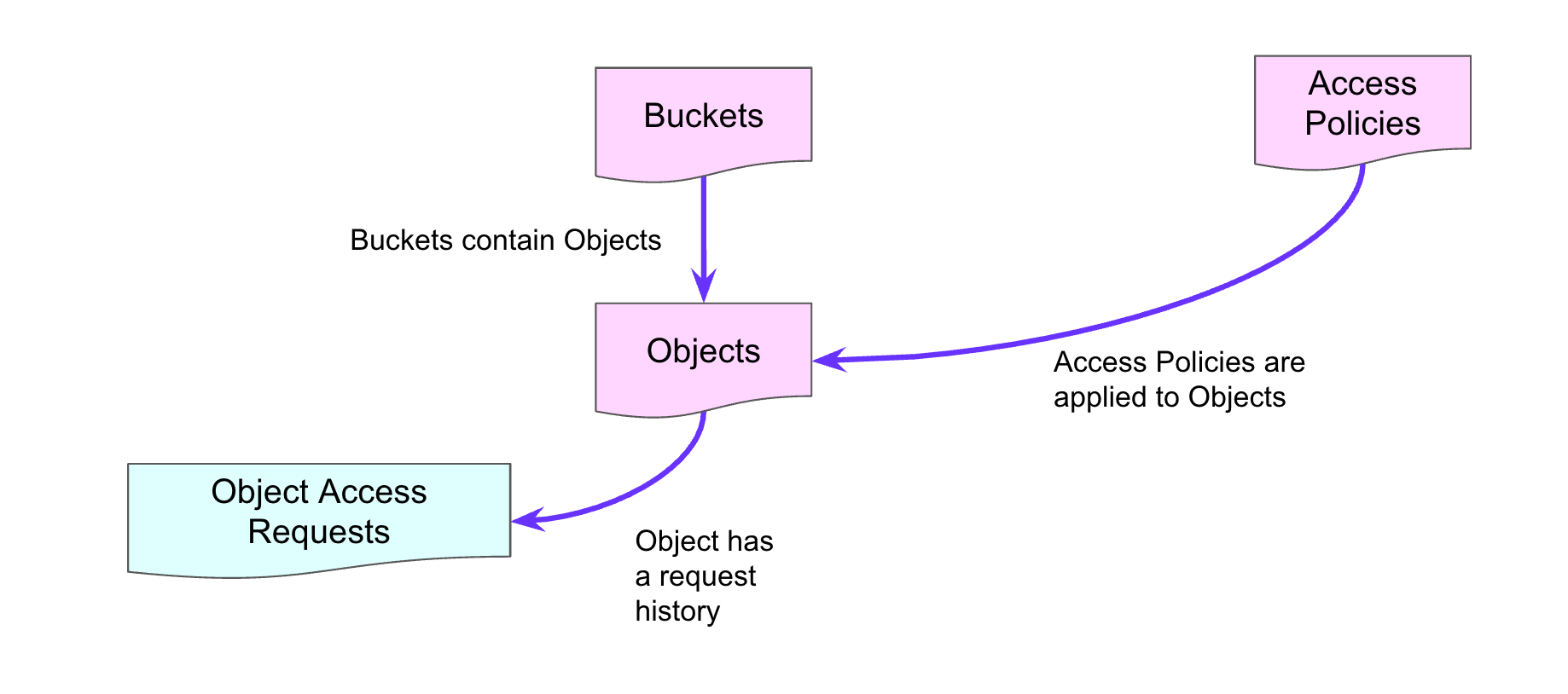
Now what about routine maintenance operations? With CockroachDB, they happen online. Below is a simple metadata example. We have an entity relationship diagram which shows 1) buckets 2) objects in those buckets we need access to 3) access rights to those buckets and 4) an object access request table for auditing access to the objects in the bucket.
Now let’s say we are running a multi-region CockroachDB deployment and we want to perform two common maintenance tasks: 1) patch a node and finalize upgrade 2) perform a schema change. We are running 3 nodes in a cluster, each running in a different AZ in US-East.
Patching a node:
We have 1 node running a different version of CockroachDB that we need to patch. First we stop the database which drains the data and connects to a different node via a connection pool. We apply the patch and the database automatically restarts. We update the cluster which recognizes that all nodes are now updated. There’s no impact to availability and a very small change in p99 latency.
Performing a schema change:
We need to make a schema change by adding a column to the buckets table. We first run a statement to alter the buckets table and add a column for the secondary owner (default is unknown so all existing records have an unknown value for that column). The database makes a copy in the background and then brings that table to the foreground. The database takes care of the changes with no impact to availability and ensures no writes to that table are lost.
For a step-by-step demonstration, check out the second half of this video:
Summary
If you are actively leveraging metadata, then you are aware of how important it is for it to always be available. Looking for an example? See how Starburst is using CockroachDB to guarantee high availability and low latency for globally distributed metadata.
If you’d like to get in touch with a Cockroach Labs expert to learn how we can help you build a foundation for always-on metadata, click here.
Special thanks to Owen Taylor and Ron Nollen, Solutions Engineers at Cockroach Labs, for providing content for this post.


