
CASE STUDY
Better audit trails with CQRS and CockroachDB
ZITADEL builds an IAM-as-a-service platform with CockroachDB & CQRS

Workload: IAM
100% Open Source
P99 latency of 10ms or less
5,600 QPS
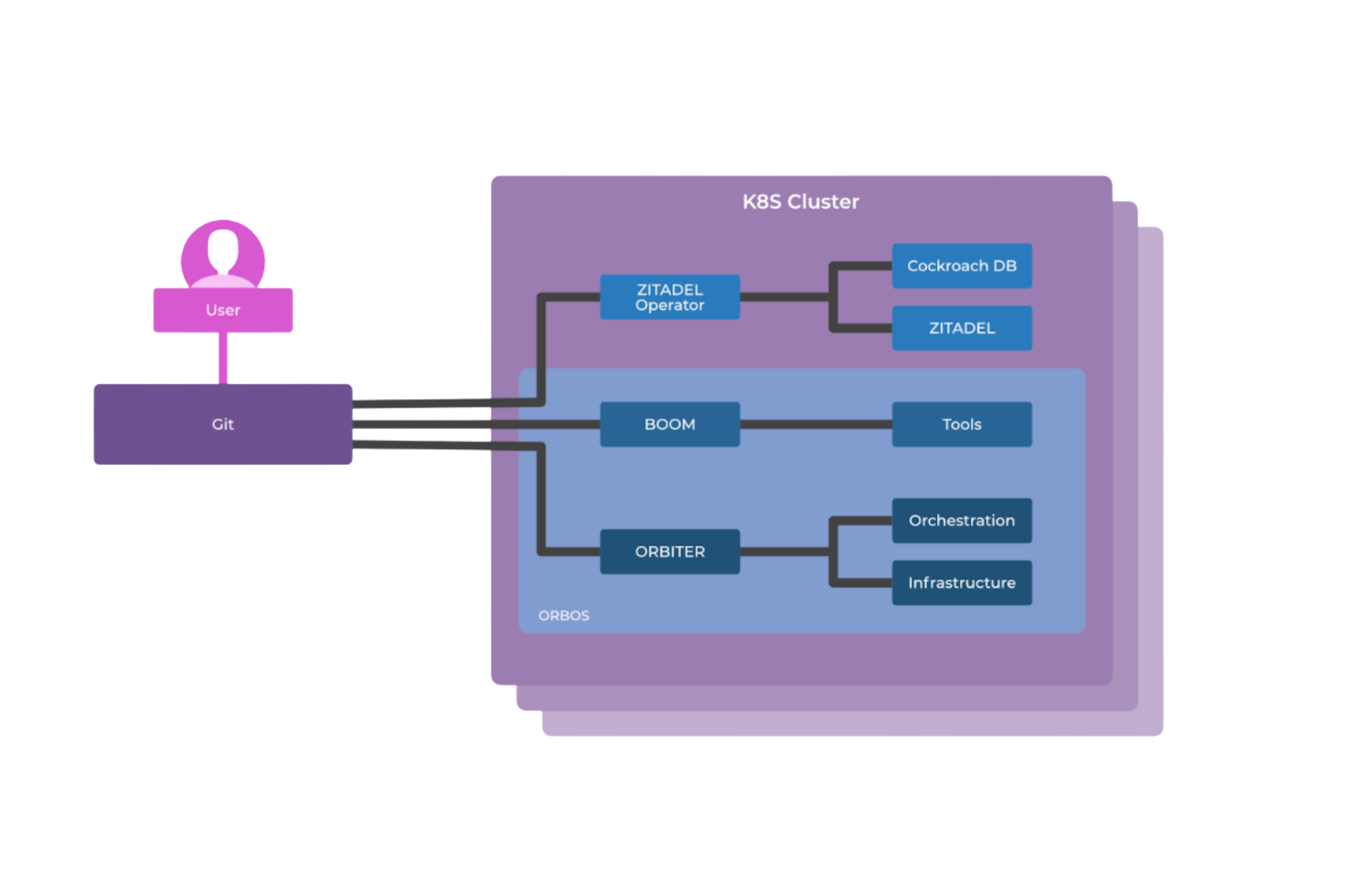
What is Zitadel?
CAOS is a Swiss-based company that is building ZITADEL — one of the first cloud-native IAM-as-a-service platforms. Based on their experience building infrastructure and IAM services at past companies, the ZITADEL engineers knew there was a gap in the market for a secure, easy-to-use Identity and Access Management system delivered as a service. With CockroachDB and CQRS, ZITADEL is running event-sourcing workloads with more detailed audit trails than the traditional IAM systems are capable of providing. With the additional detail, ZITADEL users can see everything that’s happening in the entire history of the system, which allows them to solve access problems without getting blocked by lock files.
In this report you’ll see what technical capabilities ZITADEL required for their IAM database, how data moves from the event store database to the read model database without pub/sub, why ZITADEL leverages a hybrid-cloud deployment, and what performance benchmarks they prioritized for giving users optimal experiences.
IAM Database Challenges
Building the Future of Identity and Access Management
The engineering team at ZITADEL has made an uncompromising commitment to building a system with as few external dependencies as possible. Florian Forster, an architect and the CEO of CAOS, explains, “We don’t think of individual parts. We think of the database as ‘one part’. If we deploy or manage something we deploy full clusters. And each cluster is always meant to be a highly available IAM system with all components necessary like the database, kubernetes, metrics and log collection…everything is a self-contained unit. We have a cluster with cloudscale, clusters with google cloud - if we do maintenance we maintain a cluster, not a node, not one database, not one IAM node. So we treat clusters as cattle.”
ZITADEL is a greenfield project and the engineers are making technical decisions strongly influenced by past experiences. At a previous company the people of CAOS built an IAM system using MongoDB and then Aerospike. Neither of those databases proved to be the right fit for a highly secure and easy to use identity and access management system. To build the perfect identity and access management platform Forster knew that they would need a custom system. Everything needed to be built from scratch. And the database would have to be cloud native in order to take full advantage of the flexibility of the cloud.
(Data) Chaos is inevitable
While building a prior IAM system Forster ran into problems with MongoDB. There were hurdles with operation locking and the replication of data was always a little shaky. As in, they could make it work, but it wasn’t effortless. “We don’t like the schemaless approach anymore,” Forster says. “It didn’t help us while building the previous IAM system. Because one of the things we need to solve in event-sourcing is transaction safety, for inserting writes in the right order. The whole NoSQL market is a bad fit here. You could engineer something to make it work. But SQL databases already do it. So why reinvent the wheel?”
After running into hurdles with MongoDB they switched to a traditional Key Value approach with AeroSpike. Performance improved with AeroSpike and the database was always available. But there are problems in AeroSpike regarding how to query data: Durable deletes, the open source version of Aerospike, does not include a message to delete data permanently. So data gets deleted but then reappears. Which is confusing for users. “This object was definitely deleted once, why is it back?” From this experience Forster learned that neither MongoDB, AeroSpike, or any other NoSQL or KV store databases would be the right fit for an identity and access management system (in the IAM world “LDAP” is not suitable for write workload, e.g tokens and session tracking).
Database Requirements for Identity and Access Management System
When Forster and his co-founders began searching for the right database to support their IAM-as-a-service project they developed the following requirements:
Open Source
GoLang - we built in Go, so we can see what the code does.
Kubernetes Compatible / Native
A DB that replicates and distributes data (so that they don’t have to do it themselves underneath the database)
Postgres Compatibility
Multi-Cloud
Why ZITADEL Chose CockroachDB
“Cockroach enables us to build software the way we want because the database takes care of operational problems automatically. For example if we used classic Postgres, we would have needed to think about how we operate each pods onto the servers. If we have 3 database nodes which one is the master and the slave and the read replica? With CockroachDB we don’t need to think about it. We just start 3 database nodes, and they are all concurrent. We only have to make sure our app can connect to one node. It gives us really really low friction to operate the application.” -Forster, CEO
ZITADEL chose CockroachDB after running an internal Hackathon to test it out. When they ran the chaos operator on CockroachDB the database behaved as promised. It self healed and rebalanced data across the nodes. It can handle chaos without ever requiring an application to be taken offline.
The engineers involved in the hackathon were pleased that CockroachDB speaks Postgres, and that the code is written in Go (ZITADEL uses Go and GORM). The database is easy to operate and doesn’t require any effort to scale read replicas. Also, engineers liked that CockroachDB is multi-active and that they would not have to manage Primary-Secondary configurations. Upgrades are super low maintenance as well. Recently ZITADEL upgraded to the newest version of CockroachDB and it took them three minutes to update nine nodes, without any operational impact, and a high velocity.
All those qualities were important to have, but the value of CockroachDB really started to shine when the engineers realized how perfectly CockroachDB’s architecture matches the patterns of the cloud-native applications being built by ZITADEL:
CockroachDB has a shared nothing model which fits with ZITADEL’s shared database model (the database is the only shared component of the tech stack). CockroachDB built one binary that includes everything you need - ZITADEL has one binary with everything you need for identity and access management already in it. Even when you scale ZITADEL’s system, it’s simple like CockroachDB. You say, ‘I need to scale my spoolers’ which is just a command to ask Zitadel to run spoolers. ZITADEL customers can scale from one pod to 1000 pods without any operational overhead, just like adding nodes to CockroachDB.
Building a Better Audit Trail
In ZITADEL a customer can see every operation because with CockroachDB ZITADEL can store data infinitely. This gives ZITADEL customers the ability to audit access issues without running into lock files. Often traditional IAM systems utilize lock files that are only available for temporary periods of time, like 10 days for example or they export logs to external systems (elk) which are tricky to operate at scale. Expiring access to events in the database makes it difficult to find the source of some infractions. For example, if someone is given special access to a room in an office for 6 months, and they cause a problem that doesn’t manifest right away, in traditional IAM system the lock file would prevent a company from looking back at what happened and who had access 6 months ago. In ZITADEL this is a simple query.
In ZITADEL every action by every user is tracked and stored eternally. This granularity gives ZITADEL customers a high level of security. And it saves them money because security incidents are expensive to unravel in old systems.
Event Sourcing with no Pub/Sub
The general deployment structure for ZITADEL is three different datacenters in Switzerland. One datacenter is in Google Cloud, one with cloudscale and one at a undisclosed provider
ZITADEL has taken a unique approach to event sourcing by electing not to use pub/sub. The reason not to use pub/sub is because it creates a dependency on a 3rd party tool/service that they cannot control, which conflicts with their engineering philosophy of limiting dependencies and building from scratch wherever possible. Instead of using pub/sub ZITADEL’s process looks like this: They expose the (trot style) API. Below that they have the classic CQRS architecture where the command side writes events into the event store and afterwards the spooler (schedules and fetches events) queries the database every 100MS for new events (for a certain read model) and tries to project the read model which then is used by the query side to serve people with data.
Data moves by touching the API for write/reads, then internally they just move data from eventstore to the read model by reading the spooler over. (Reading the events and generating the new model - this is a scheduled process that runs in the background.) The eventstore is transaction safe, but the read model runs about a second behind. Which is fine for IAM because they prioritize latency on read traffic not write traffic. Most of the traffic they have is from log-in experiences. So a user logs in and afterwards the session gets consumed over, and over, and over again. Which means there is a lot of read traffic but not much write traffic.
The log-in system prioritizes reducing cache as much as possible and making data easy to query. In this system a user inputs a username and then a password has a table in the database where they look up user names directly. Afterwards they use the ID to get the password hash. So they just have a simple table with username and Password hash. This means they don’t yet need secondary indexes for optimization (but they might eventually).
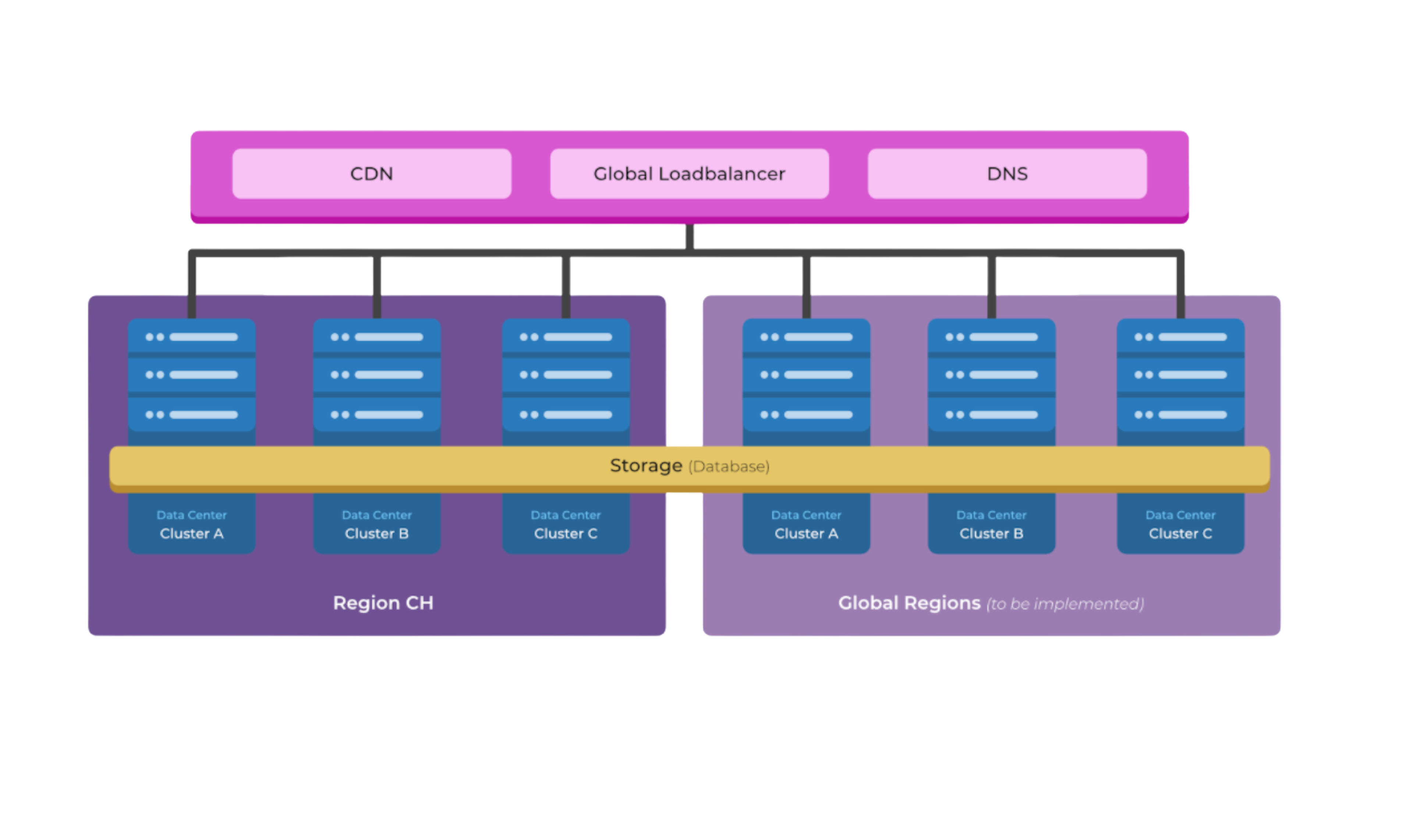
Benefits of Multi-Cloud & Multi-Region Application Architecture
“We architect to survive availability zone failures.” -Forster, CEO
Resilience
The first benefit of Multi-Cloud and Multi-Region architecture is resilience. With their clusters in three different availability zones and three different clouds ZITADEL is prepared to survive if any one of those availability zones goes down (which can happen).
To prepare for availability zone failures ZITADEL intentionally destroys clusters everyday, without any operational impact. (This resilience is a strength of CockroachDB. Nodes can be blown out, then restarted, and all is well in five minutes.) ZITADEL architecture requires that there are always three different availability zones in one region. Right now, Zitadel only operates in their Switzerland region. But when they scale the business to other parts of Europe they will add three availability zones to each new region.
Flexible Data Storage Options
Some customers of ZITADEL prefer to keep their data in a public cloud. Others would rather keep their data on-prem. And more customers would like to keep data both on-prem and in a cloud. CockroachDB data can go wherever it needs to go.
This is one characteristic of CockroachDB that makes it a great fit for a managed service. ZITADEL can package up CockroachDB in their IAM as-a-service and they don’t have to restrict where data can be stored. This flexibility helps ZITADEL deliver an IAM system that gets deployed by customers in an average of 22 minutes. Other comparable IAM services take an average of 5 days.
CockroachDB really works well in cloud native environments. ZITADEL can go to a customer and deploy CockroachDB on their Kubernetes cluster and it just works. Other databases need to be tricked into running on Kubernetes or you need to really optimize it for each customer use case. Which is an approach that ZITADEL would never choose. Instead, they use Cockroach.
Data Privacy & Low Latency in Multi-Region Architecture
Right now ZITADEL is experimenting with keeping the data for a user in one datacenter, while routing the traffic through whichever datacenter is closest to the user. If a user is on vacation in Germany they route traffic with Cloudflare to a cluster in Germany. The cluster in Germany will query the local database. If the data is not there, the database will relay the query to another database (located in Switzerland). CockroachDB relays this traffic very well.
This experiment is based on the need some customers have for data to be moved around for global availability. And the need some customers have for data to be pinned within specific geographic boundaries for data privacy reasons.
The enterprise version of CockroachDB has a geo-partitioning feature that makes it possible to pin user data to a location at the row level (as opposed to having to manage the data location in the application layer). This is a feature that ZITADEL will eventually need.
Application & Database Performance
All of ZITADEL’s APIs respond to 80% of queries in under 250 milliseconds. This benchmark is non-negotiable. Against the database ZITADEL currently averages sub 10ms latency and is optimizing the system to serve 90% of traffic in under 5ms. To do this they operate the API’s as close as possible to the database. And they use NVME disks for storing data within the data centers, with no replication below the database (because CockroachDB automatically handles replication).
ZITADEL Cluster Details
Each cluster has 3 database nodes and 3 application nodes, and each database node has 2CPUs and 8 gigs of memory. They are small by design due to their topology. With smaller nodes they can easily pump the traffic in because it’s so highly optimized.
This standard cluster computes around 8,000 authentications per second. The authentications process is the most expensive for ZITADEL because the password hashing and other functions loads the system up more than any other queries.
The Data Inside CockroachDB
CockroachDB serves as ZITADEL’s general purpose database, which means it stores everything. A lot of the data is all related to the Organization Units of ZITADEL customers. The users, the projects, the clients and rows in the projects, and the single sign on objects. There is a whole variety of IAM objects stored by ZITADEL. For example: Organizations, Users, Sessions, Clients.
Using JSONB as Temporary Storage
Inserting data without creating schemas upfront is useful and worked perfectly out of the box.
For ZITADEL, there are occasions when a user is redirected to them from an application. The user shows up with a bunch of unstructured data (headers might not be there for example). ZITADEL stores this unstructured data with JSONB until they can serialize them into events.
Elastic scale with CockroachDB
“With CockroachDB we can scale our ops business without big changes to architecture and without needing to reinvent the wheel each time we need to scale. We can scale elastically from really small systems to really big systems. We don’t need to hold a high oversubscription quota to do it,” -Forster, CEO
User Growth & Geo-Paritioning
The resilience, scalability, and low maintenance qualities of CockroachDB made it the perfect fit for ZITADEL’s Cloud-Native IAM-as-a-service system. ZITADEL has separated itself from the competition by offering an IAM system that is highly secure (with a best-in-class Audit Trail) and is easy to use (average set it up is 22 minutes). ZITADEL could not have used Mongo, Aerospike, or Postgres to build a system with so few dependencies on external tools and so little operational overhead for the engineers. None of those databases can automatically take care of the operational challenges in an event sourcing workload the way that CockroachDB does.
Today, ZITADEL is available in one region and they’re using the Open Source version of CockroachDB. In 6-12 months they will begin to scale to Germany and other regions, at which time they’ll utilize the geo-partitioning feature of CockroachDB to pin user data within geographic boundaries. Customers can tell ZITADEL that they want their data to stay within a specific boundaries for compliance reasons and the database will take care of it.
There’s also a machine learning use case in development. ZITADEL will leverage all the old “events” stored in CockroachDB to create “threat models.” For example if a user always logs in with windows at the same location then ZITADEL could predict the risk of a breach when the location or OS changes. The future for ZITADEL and its customers is bright (and safe).
