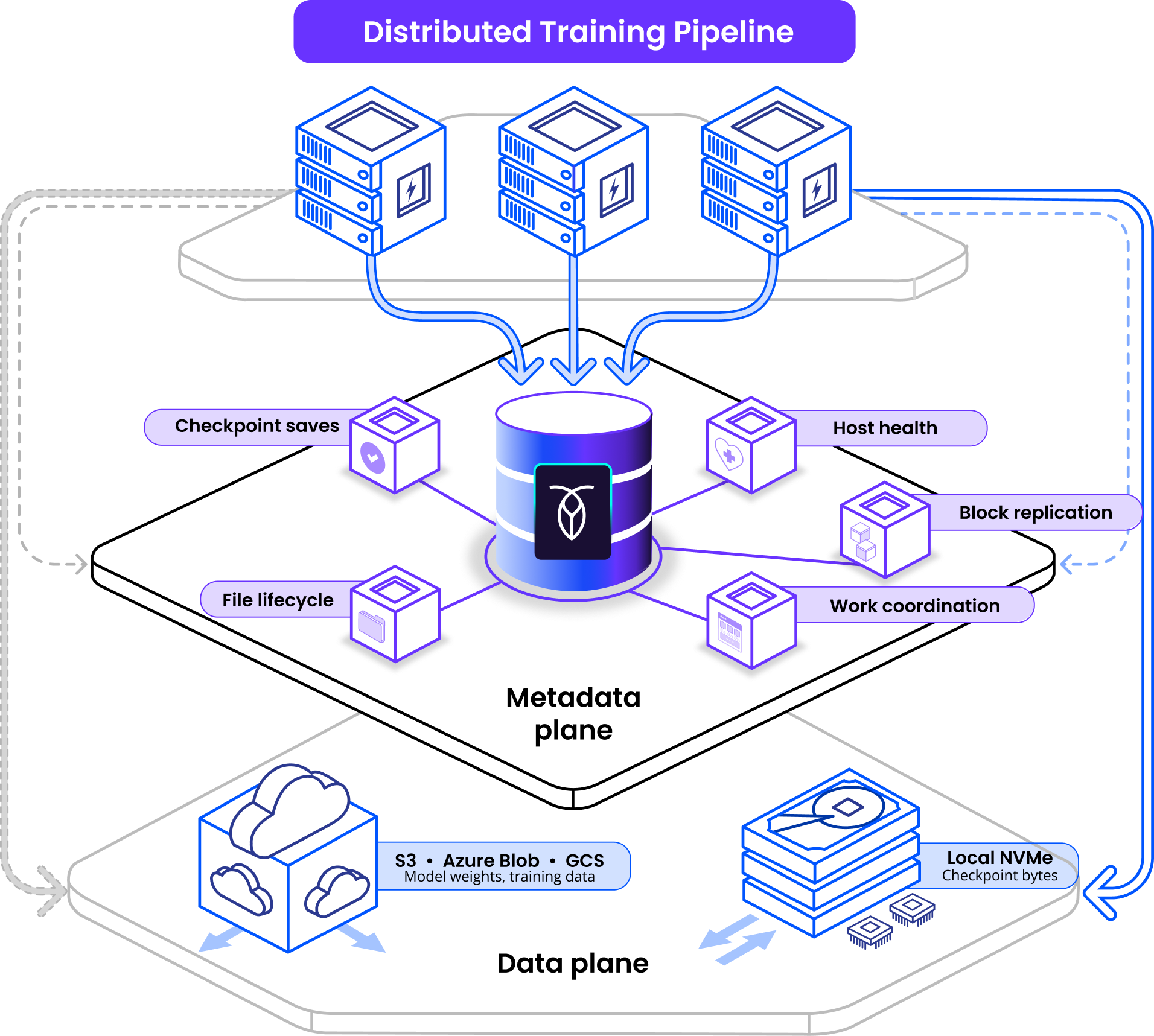
The coordination layer your training pipeline can't outgrow.
Reinforcement learning at scale requires a reliable underlying distributed system. Thousands of GPU workers write checkpoints, read training inputs, track host health, and coordinate ownership concurrently, at millions of QPS, on bare metal where nodes fail regularly.
Production QPS today at a leading AI lab
100k
QPS in sight for 2026
3.5M+
3-year QPS target, multi-cluster
100M+
Before
The Frankenstein Stack: What most teams are running today

Every RL training run has a database problem
When you scale reinforcement learning to thousands of GPU workers, you create a distributed file system coordination problem. Workers flush model checkpoints simultaneously at each training step. They read task definitions, prompts, and tool configs at training start. They track which hosts are healthy and trigger re-replication when nodes go down.
Most teams are stitching together Redis for coordination, PostgreSQL for metadata, SQLite for local state, and a custom lock manager for shard ownership. Eventual consistency in any layer creates silent data loss. Under-replicated blocks look fine until hours later when training data is gone. Four systems to secure, back up, and debug — at three in the morning, when your seven-day run is failing.
After
CockroachDB: One metadata plane replaces all of it

One metadata plane for your entire training pipeline
CockroachDB stores the coordination state that makes your distributed storage system work at scale. Checkpoint saves, host health tracking, block replication, work coordination, and file lifecycle state machines — all in a single PostgreSQL-compatible database. ACID guarantees are on by default, so every worker on every node sees consistent state — at all times.
CockroachDB does not store model weights, training data, or checkpoint bytes. That lives in object storage (S3, Azure Blob, GCS) or local NVMe. Think Google Colossus metadata, not the actual data.
Coordination, state & metadata in one DB
Linear scaling to millions of QPS
Zero-downtime automatic resilience
Bare-metal ready
Plans for every stage of the application lifecycle
Horizontal write scale without manual sharding
PostgreSQL walls at ~50K QPS. Redis can't durably persist at this volume. CockroachDB's multi-writer architecture scales horizontally to 100M+ QPS without manual sharding.
Zero-downtime failover for multi-day training runs
You can't restart a seven-day training run because the database went down. CockroachDB survives node failures automatically with 3x (and more) replication built-in. Bare-metal ready with Enterprise Operator for automatic disk failure handling.

ACID guarantees prevent silent data loss
Eventual consistency creates training data loss bugs that are catastrophic and nearly impossible to debug. When your replication checker says a block has 3 replicas, that has to be true. CockroachDB's serializable isolation means file lifecycle state machines are safe under failure, so bugs surface in seconds, not hours.

One system your team already knows
Stop operating Redis + PostgreSQL + SQLite + a custom lock manager under production pressure. CockroachDB handles coordination, durability, and ACID in one system. It's PostgreSQL wire-protocol compatible, so your existing tooling works out of the box: Rust (sqlx), Python (asyncpg, psycopg3), and any PostgreSQL driver.

“AI models are growing in size and complexity, and we wanted to build a solution for our customers that would allow them to leverage their AI workloads with speed and efficiency. This also meant that we needed a reliable, horizontally scalable database that could deliver the most up-to-date data without spending a lot of time on maintenance. We decided to use CockroachDB to power our AI Object Storage service, and we've been pleased with the results. CockroachDB is durable, provides strong data consistency guarantees, seamlessly scales, and helps simplify operations.”
Dana Renfrow
Engineering Manager, Coreweave
Built for where RL Training is going — not where it is today.
CockroachDB is the globally resilient data foundation trusted by leading AI platforms and Fortune 500 enterprises. Start with checkpoint metadata and host health tracking. Add distributed work coordination when your cluster scales. Grow to full metadata plane architecture at 100M+ QPS. No migrations, no rewrites, no architectural fragmentation.