

What is a data pipeline?
A data pipeline is a piece of software that ingests data from one or more sources, and moves that data to one or more destinations. Often, the data is transformed as part of this process to ensure that it meets the requirements of the system or systems it is being sent to.
In other words, a data pipeline is software that “pipes” data from one system to another. Just as a city water system might collect water from a local aquifer, clean the water in a treatment plant, and then pump it into homes throughout the city, a data pipeline collects data from various data sources, cleans and transforms it, and then pipes it to other systems such as analytics databases.
Data pipelines may be custom software that is built and maintained by a company’s engineers, or they may be third-party software tools with pre-made integrations that can connect to and transform data from a variety of popular data storage platforms.
Why use a data pipeline?
There are a variety of reasons that a company might choose to implement a data pipeline, but one common example is analytics. An analytics team will want to examine and analyze data from a variety of sources across the company. Generally speaking, it makes more sense – both for employee efficiency and for system performance – to consolidate that data in a separate analytics database rather than having the analysts query the various production databases.
For example, let’s imagine a simple example of a banking application. The application allows customers to deposit, transfer, and withdraw money, and stores all of the data related to those transactions in a SQL database.
The bank’s analysts will want to dig into this data, but they don’t want to impact the performance of that database by constantly running queries against it. They will also want to analyze other company data that’s not stored in the transactions database, such as employee data, company financial data, user demographic data, and more.
So, they implement a data pipeline that ingests data from the transactional database and their other data sources, transforms it into their preferred format, and pipes it into an analytics database. That way, they have all the data they need in one place, and they can query that database without impacting performance on any other company systems.
Do I really need a data pipeline?
While almost all companies have the need to move data from one place to another, it’s worth noting that a separate data pipeline isn’t always needed to accomplish this. Next-generation databases often come with pipeline-like features built-in, which can reduce the need to rely on separate pipelines.
For example, if a company is using CockroachDB as its transactional database, it could leverage CockroachDB’s built-in changefeeds and CDC queries feature to automatically transform and then send the desired data to its destination in near-real-time.
In practice, though, few companies use advanced databases for all of their use cases. And even when they do, these features may not support all of the desired transformations or merges with data from other data sources, so pipelines are often required.
RELATED
When (and why) you should use changefeeds
Data pipeline architecture example
Here’s a simple example of how a data pipeline fits into the larger tech stack of a company, such as the hypothetical bank described above.
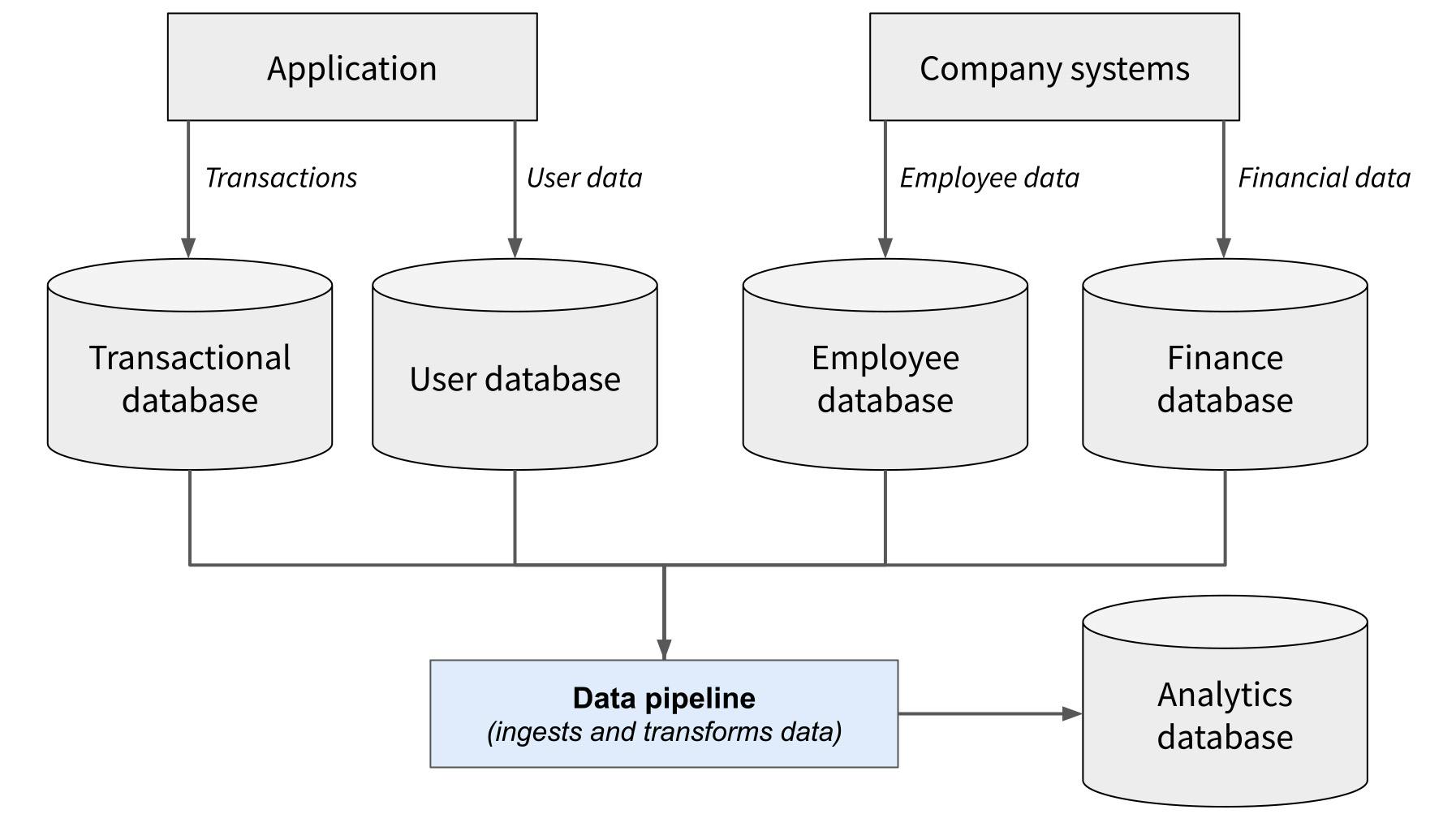
But of course, this is just a simple example of one type of data pipeline. Let’s take a look at some of the different types of data pipelines.
Batched vs. streaming data pipelines
Data pipelines that use batched processing are generally implemented to handle analytics tasks that are not extremely time-sensitive, and that involve large amounts of data. For example, in the case of monthly financial analysis, a batched processing system might be implemented to ingest and move data from production databases to the analytics database once per week during off-peak hours. This minimizes the performance impact on the production database, and the fact that data isn’t immediately available in the analytics database doesn’t matter.
Streaming data pipelines are used when the data is time-sensitive, and it needs to be moved to the destination system as soon as possible. For example, imagine a video streaming service that makes recommendations based on user activity. To make good recommendations about what to watch next, the system has to know what the user is currently watching. This generally means that data from a user activity database must be quickly piped into an analytics database for use by the recommendation engine.
Generally speaking, batch processing systems are considered more reliable, as streaming systems are more susceptible to problems like connectivity drops and traffic surges, where individual data events can get backed up in a messaging queue or lost. However, many use cases require real-time or near-real-time data syncing, in which case a streaming data pipeline is the superior option.
ETL vs. ELT
ETL and ELT are terms that describe the order of operations for data pipelines.
ETL stands for Extract, Transform, Load, and describes a system where data is extracted from the source database, transformed in the pipeline, and then the transformed data is exported to the destination database.
ELT, which stands for Extract, Load, Transform, describes a system where the data is extracted from the source database and piped directly to the destination database. The destination database accepts this raw data and either performs the needed transformations itself or simply stores the raw data for future cleaning, processing, and analysis by humans or other systems.
How to build a data pipeline
While the specifics required for each data pipeline will differ based on use case, building a basic data pipeline is actually fairly straightforward.
While a full coding tutorial is outside the scope of this article – and the code would depend on your programming language of choice anyway – here’s an outline of the elements most pipelines need:
Connection. Authenticate and create a connection to each of your data sources.
Extraction. Select and extract the desired data from those sources.
Cleaning. Perform preprocessing tasks such as dropping duplicates and null values in the data (as needed).
Transformation. Transform the data as desired to prepare it for the destination. This may involve additional data cleaning, merges and joins with data from other sources, calculating aggregate statistics, etc.
Connect and export. Authenticate and connect to your data’s destination, and then send the transformed data there for storage and future use.
Of course, in some use cases a pipeline may need additional features, or it may not need some of the above elements. In an ELT pipeline, for example, the cleaning and transformation elements won’t be needed, as the destination database can accept raw data.


