
CockroachDB empowers developers to build fast, scalable applications, and one of the ways it does this is by providing rich, Postgres-compatible SQL. And while CockroachDB follows the Postgres wire protocol, the database also has a custom SQL implementation designed for a distributed database.
Over the years, we’ve expanded our distributed SQL implementation to include a cost-based optimizer (CBO) and vectorized execution engine - all built to tackle the complexity of distributed data for developers. In CockroachDB 20.2, we’re excited to provide developers with an increasingly rich SQL feature set that includes support for spatial data, materialized views, Enums, ALTER TABLE, and user-defined schema changes. Let’s dive into the new capabilities.
More powerful, flexible data models in CockroachDB
Applications today need to define expressive data models and be able to continuously evolve them as application requirements change.
Spatial data in CockroachDB
CockroachDB now supports the ability to model spatial data which includes both geometric, related to a map, data and geographic, related to the Earth’s surface, data. To read more about combining PostGIS compatible SQL with CockroachDB’s scalability, check out spatial data tutorials or take a look at this distributed spatial data demo.
User-defined schemas in CockroachDB
Developers using Postgres can leverage a hierarchy of database → user-defined schemas → database objects (tables, views, etc…) to organize their data. Data organization patterns can support multiple users or multiple applications working within the same database cluster isolated from each other. In addition, Postgres has a large third-party tool ecosystem that can leverage user-defined schemas in their native internal implementation. Prior to 20.2, we recommended users create a database wherever they would create a user-defined schema, and third-party tools needed to use workarounds.
With 20.2, user-defined schemas are supported in CockroachDB. Developers can use the example below to convert databases with only the default public schema to be user-defined schemas. CockroachDB developers can now implement a data hierarchy similar to what they would use in Postgres. In addition, CockroachDB developers still have the flexibility to execute statements against databases beyond the current connected database with fully qualified names.
With the additional level of namespacing provided by user-defined schemas, developers can create more complex and secure data hierarchies. The example below shows that a single database for an application can support user-defined schemas for different users. Support for user-defined schemas also removes a known blocker for developers who are adding third-party tool support for CockroachDB. For example, Prisma - the Javascript data access framework - ran into this very issue.
demo@127.0.0.1:53365/defaultdb> show databases;
database_name | owner
----------------+--------
defaultdb | root
teamA | demo
movr | demo
postgres | root
system | node
(5 rows)
demo@127.0.0.1:53365/defaultdb> create database my_app;
CREATE DATABASE
demo@127.0.0.1:53365/defaultdb> use my_app;
SET
demo@127.0.0.1:53365/my_app> ALTER DATABASE teamA CONVERT TO SCHEMA WITH PARENT my_app;
CONVERT TO SCHEMA
demo@127.0.0.1:53365/my_app> create role teamA;
CREATE ROLE
demo@127.0.0.1:53365/my_app> alter schema teamA owner to teamA;
ALTER SCHEMA
demo@127.0.0.1:53365/my_app> show schemas;
schema_name | owner
---------------------+--------
crdb_internal | NULL
information_schema | NULL
teamA | teamA
pg_catalog | NULL
pg_extension | NULL
public | admin
(6 rows)
Enumerated types (Enums)
Using Enums in a data model provides stronger data integrity and can be combined with Enums available in most programming languages to validate data at both the application and database layer. Stronger data validation allows developers to think about other technical challenges. An Enum defines a list of static values and can be set as a column’s type. Enum columns permit only values in a user-defined set, such as items in a user interface dropdown.
teamA@127.0.0.1:53365/my_app> CREATE TYPE movie_genre AS ENUM ('drama', 'comedy', 'horror');
CREATE TYPE
teamA@127.0.0.1:53365/my_app> CREATE TABLE employees (favorite_movie_genre movie_genre);
CREATE TABLE
teamA@127.0.0.1:53365/my_app> INSERT INTO employees VALUES ('action');
ERROR: invalid input value for enum movie_genre: "action"
SQLSTATE: 22P02
Online schema changes with ALTER TABLE
In 20.2, we’ve expanded CockroachDB’s support for online schema changes. These features allow developers to model the relationships their application needs and change data models over time. When combined with CockroachDB’s online schema changes, developers can perform such changes without application downtime.
With ALTER TABLE...ALTER COLUMN...TYPE, developers can now change a column’s type. ALTER TABLE...ADD COLUMN...REFERENCES syntax supports adding foreign keys to newly created tables in the same transaction as shown in the example below.
Schema changes are a natural part of the application development lifecycle. The initial schema needs to evolve to support future business needs or to add previously unknown business constraints.
demo@127.0.0.1:53365/my_app> BEGIN;
BEGIN
demo@127.0.0.1:53365/my_app> CREATE TABLE employees (id INT PRIMARY KEY);
CREATE TABLE
demo@127.0.0.1:53365/my_app OPEN> CREATE TABLE laptops (id INT);
CREATE TABLE
demo@127.0.0.1:53365/my_app OPEN> ALTER TABLE laptops ADD COLUMN employee_id INT REFERENCES employees (id);
ALTER TABLE
demo@127.0.0.1:53365/my_app OPEN> COMMIT;
COMMIT
demo@127.0.0.1:53365/my_app> SHOW CREATE laptops;
table_name | create_statement
-------------+---------------------------------------------------------------------------------------------------------
laptops | CREATE TABLE public.laptops (
| id INT8 NULL,
| employee_id INT8 NULL,
| CONSTRAINT fk_employee_id_ref_employees FOREIGN KEY (employee_id) REFERENCES public.employees(id),
| FAMILY "primary" (id, rowid, employee_id)
| )
(1 row)
Improve application performance
CockroachDB performance improved significantly on real-world OLTP workloads as evident by our TPC-C benchmarking results, the industry standard for OLTP benchmarks. In addition, Cockroach Labs continues to invest in servicing queries that read a lot of data, such as complex joins and aggregations found within transactional workloads.
Using TPC-H queries as representative analytical queries, we saw a decrease in query latency for 20 out of the 22 queries with query 9 latency improving by 80x.
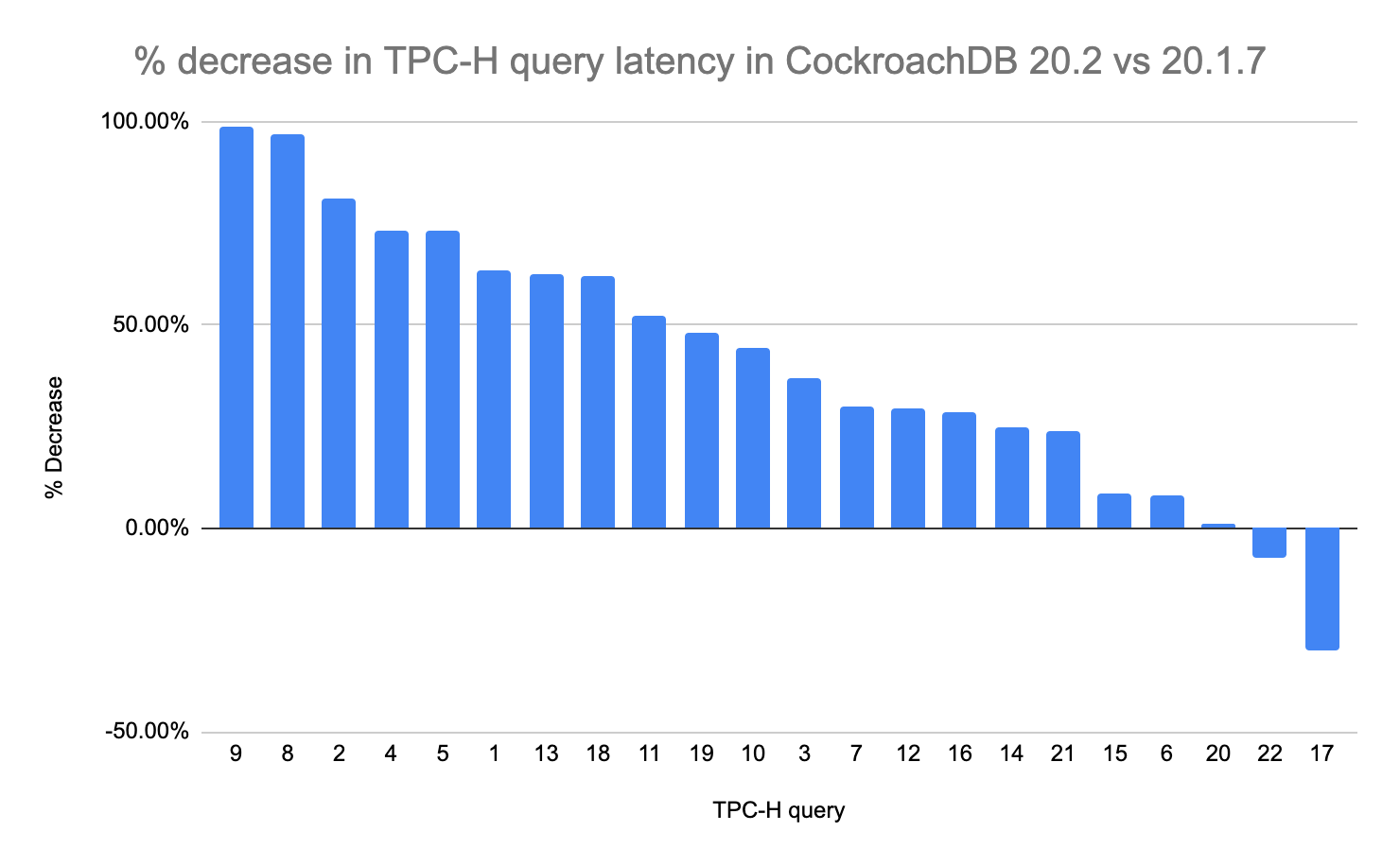
In 20.1, CockroachDB’s vectorized execution engine was only on for a subset of queries. 20.2 will have the vectorized execution engine on by default for many more complex joins and aggregations. The vectorized execution engine allows for better memory accounting that was not possible with the row-oriented execution engine. To read more about how we built a vectorized execution engine, check out this post.
We also improved the performance of lookup join and join reordering, two critical database components whose performance affects many queries. While changes to lookup joins benefitted most TPC-H queries, it negatively affected Query 17 increasing the latency. This highlights the tricky path of optimizing execution across many queries, and Cockroach Labs continues to analyze for new improvements. The join-reordering algorithm is a part of CockroachDB’s cost-based optimizer (CBO), which continues to become more intelligent with every release as our team incorporates field learnings to select the best query execution plan.
With vectorized query execution, better lookup joins, and improved join-reordering, CockroachDB has increased its execution efficiency allowing developers to do more with the same database resources. CBO enhancements mean that queries will have better performance without developers having to understand the complexities of query execution. Instead, developers can focus on their application technical challenges.
CockroachDB supports materialized views and partial indexes
CockroachDB now supports materialized views and partial indexes that developers can employ to improve their application performance.
Materialized views allow developers to store query results as a queryable database object. A materialized view acts as a cache of a query’s results, which can be refreshed using REFRESH MATERIALIZED VIEW. With materialized views, developers can efficiently access query results with the tradeoff that materialized view data will be out of date as soon as the underlying query data changes. This data model can support use cases such as a daily report of business activity for which having real-time data is not important.
For an application, certain query access patterns can be well-defined and only operate against a subset of data. Partial indexes can help optimize these query patterns with a lower impact on write performance compared to full indexes. Since an index is another copy of data, a partial index means that not every write to a table would incur the overhead of updating a full index and stores less data.
Most applications have queries that are critical to their use case or help achieve service-level objectives (SLOs). Once these scenarios have been identified, CockroachDB provides developers with a wide range of strategies including materialized views and partial indexes to help achieve application requirements.
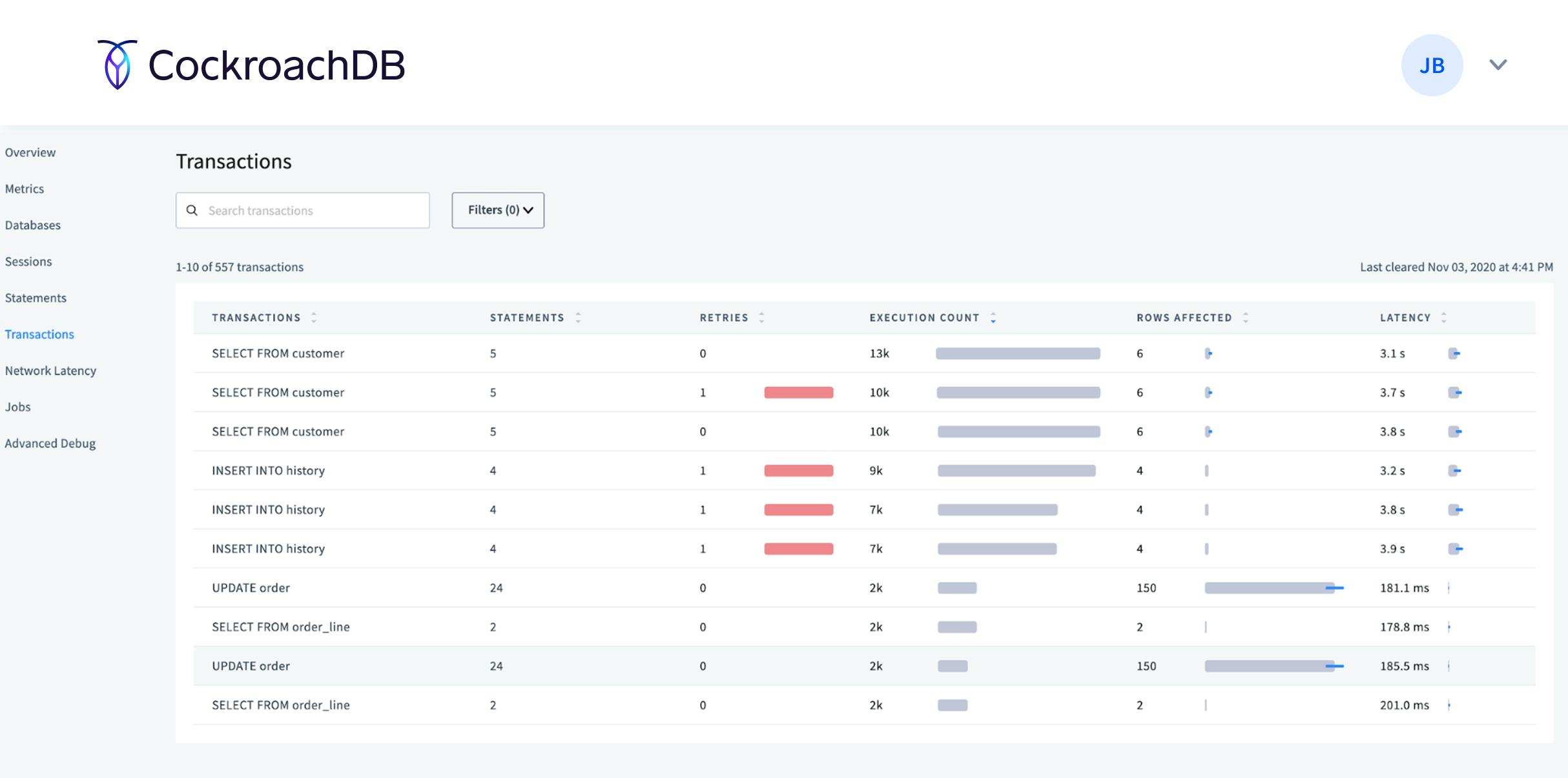
Troubleshooting CockroachDB
In 20.2, Cockroach Labs increased the ways to introspect the database both from our cockroach sql command line and Admin UI. This includes new ways to introspect database sessions and transactions.


Conclusion
CockroachDB provides developers with the familiar interface of Postgres-compatible SQL against a database that is designed to scale without additional application complexity. Developers can take advantage of the SQL features above to create and alter complex, performant data models. Improvements to our Postgres-compatible SQL reduces overhead for third-party developer tools to add CockroachDB support.
In 20.2, Cockroach Labs was excited to partner with the developer community to add Hibernate and Active Record support. As Cockroach Labs continues to provide developers with more solutions to their problems, we are committed to investing in CockroachDB’s CBO, vectorized execution engine, and other internal mechanisms that improve overall database performance.
Check out the power capabilities discussed above by trying out CockroachDB Dedicated.


