

In CockroachDB, we use the Raft consensus algorithm to ensure that your data remains consistent even when machines fail. In most systems that use Raft, such as etcd and Consul, the entire system is one Raft consensus group. In CockroachDB, however, the data is divided into ranges, each with its own consensus group. This means that each node may be participating in hundreds of thousands of consensus groups. This presents some unique challenges, which we have addressed by introducing a layer on top of Raft that we call MultiRaft.
With a single range, one node (out of three or five) is elected leader, and it periodically sends heartbeat messages to the followers.
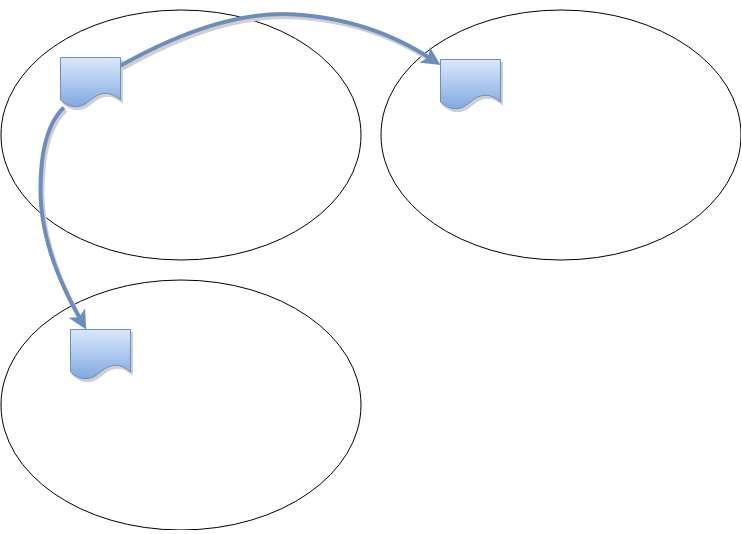
As the system grows to include more ranges, so does the amount of traffic required to handle heartbeats.
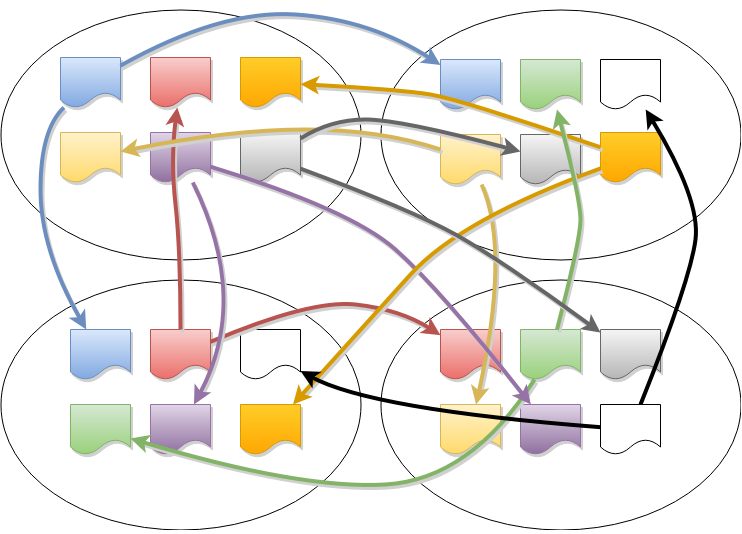
The number of ranges is much larger than the number of nodes (keeping the ranges small helps improve recovery time when a node fails), so many ranges will have overlapping membership. This is where MultiRaft comes in: instead of allowing each range to run Raft independently, we manage an entire node’s worth of ranges as a group. Each pair of nodes only needs to exchange heartbeats once per tick, no matter how many ranges they have in common.
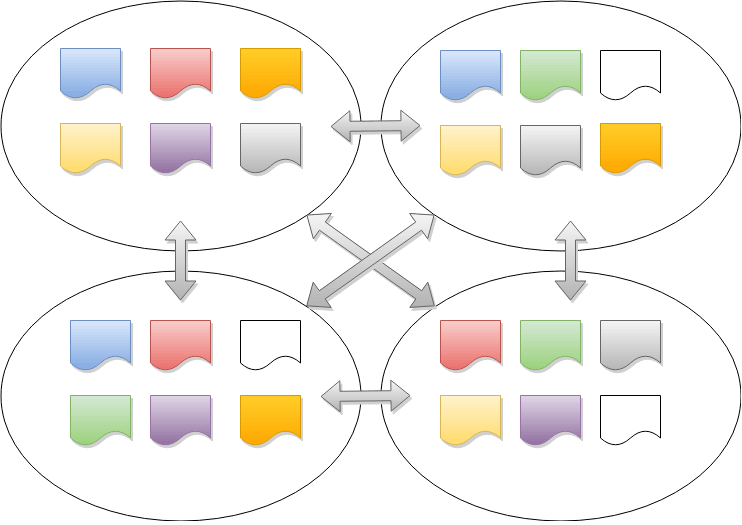
In addition to reducing heartbeat network traffic, MultiRaft can improve efficiency in other areas. For example, MultiRaft only needs a small, constant number of goroutines (currently 3) instead of one goroutine per range.
Implementing and testing a consensus algorithm is a daunting task, so we are pleased to be working closely with the etcd team from CoreOS instead of starting from scratch. The raft implementation in etcd is built around clean abstractions that we found easy to adapt to our rather unusual requirements, and we have been able to contribute improvements back to etcd and the community.


