


AWS’s us-east-1 region stumbled last month, and the businesses buckled. Our customers didn’t. CockroachDB clusters continued serving global traffic without disruption – proving what “resilience by design” really means.
Venmo, Reddit, Snapchat, airline ticketing systems, and thousands more applications froze when one of the world’s busiest cloud clusters went dark. Their customers quickly felt the pain as payments stalled and support systems overloaded. Everyday necessities like video calls, rideshares, and online checkouts suddenly failed.
This was the third major us-east-1 outage in five years, and each time the impact hits harder. It’s not just a cloud failure headline, so much as a data architecture reckoning. As our CEO and Co-Founder Spencer Kimball put it in the hours following the event:
“Today’s AWS outage is a wake-up call for every business: if your stack depends on a single region or has hard dependencies on services that do, you’re prone to losing business continuity in the event of this class of cloud provider outages.”
What is the hidden dependency trap?
It’s convenient for enterprises to assume that the cloud will absorb failure for them, but that doesn’t reflect reality. The Internet actually rests on a fragile web of shared dependencies: control planes, DNS systems, and load balancers that are often concentrated in the same handful of hyperscaler regions. When one domino falls, others follow.
This wide-ranging vulnerability stems from what Kimball has often called cloud monoculture. “We’ve optimized for convenience,” he observes, “and built entire industries on identical stacks, single clouds, and tightly coupled dependencies. But when everyone’s running the same playbook, a single failure becomes a systemic event. What started as ‘efficiency’ is now fragility at scale.”
“And the risk compounds as companies grow,” continues Kimball. “A handful of U.S. cloud hyperscalers now underpin most of the world’s software – the same few platforms power banking, healthcare, logistics, and AI. When everything runs on the same substrate, a single failure doesn’t just take down one service; it can disrupt entire economies. Every acquisition, every integration, expands that shared risk.”
Even multi-AZ setups can mask hidden single points of failure: a load-balancer subsystem, a DNS misroute, or a database API dependency that ties everything back to a single geography. When us-east-1 failed, the ripple effect was global, with a disproportionate impact on teams that overlooked fault tolerance planning while optimizing for speed and cost. For companies that built beyond the default assumptions, however, the outage barely registered.
Performance under Adversity: Continuity vs. recovery
Resilience isn’t what you do after an outage. It’s what your system does while it’s happening.
On October 20, the AWS’ issues kicked off, as increased error rates and latencies were triggered by “DNS resolution issues for the regional DynamoDB service endpoints.” The next to crash was AWS's elastic compute service, EC2, which is dependent on DynamoDB services for its own internal operations. From there, health check failures began to cripple the Network Load Balancer, leading to connectivity problems for CloudWatch, Lambda, and many more AWS services.
A long list of major apps preceded to go offline. Affected FinServ apps included Chime, Robinhood, and Venmo; social and productivity apps like Snapchat and Zoom; and media/gaming services such as Epic Games and Crunchyroll.
At Cockroach Labs we test how CockroachDB stands up to real world pressure. Regional outages are one of seven scenarios in our Performance under Adversity benchmark, a methodology for proving that our database’s distributed SQL clusters stay consistent and responsive, even as infrastructure fails beneath them.
During the latest AWS incident, CockroachDB Cloud clusters worldwide continued to process business-critical workloads without interruption. Our VP of Engineering, Jordan Lewis, summed it up:
What a day! I'm happy to note that Cockroach Labs was serving up business as usual today.
A massive thank you to everyone working hard to repair the entire internet right now. 🫡
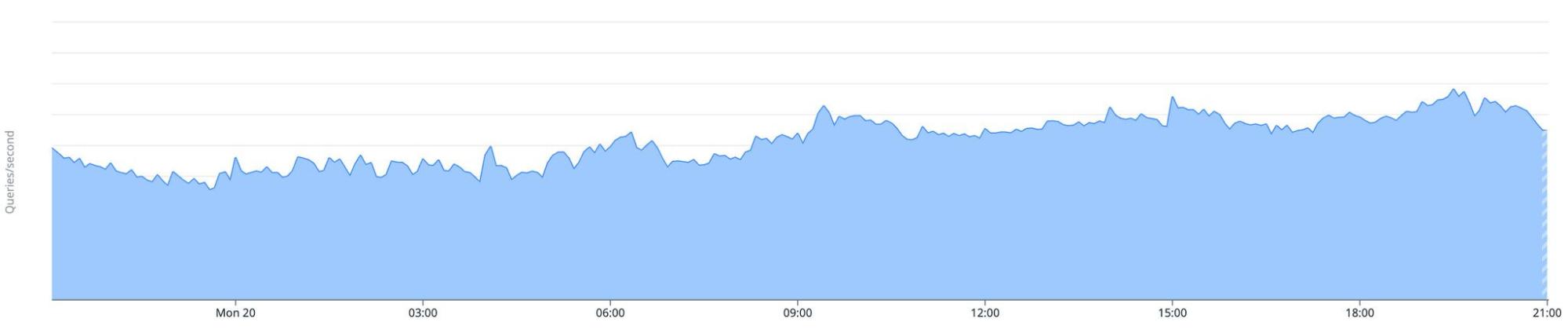
Caption: CockroachDB Cloud customer query volume remaining stable during the Oct 20 AWS outage.
In the chart above, you can see that CockroachDB Cloud clusters served queries without interruption during the AWS outage. While many services experienced interruption, CockroachDB's distributed architecture ensured an uninterrupted database experience even while the broader Internet was suffering.
Lest anyone think this kind of resilience comes easily…it doesn’t. Some database providers experienced multi-hour disruptions triggered by the same regional event. Building fault-tolerant systems is hard. Doing it at scale, automatically, and without sacrificing correctness is harder still.
Why is survivability the new scale metric?
The past decade was defined by scale: How fast could you grow users, data, and compute? Now that scale is inseparable from survivability: how well you withstand failure without breaking user trust.
The stakes here are not “in theory.” According to Cockroach Labs’ 2025 State of Resilience Report, 100% of companies surveyed experienced revenue losses from outages in the past year, with per-incident losses ranging from $10,000 to over $1 million. Larger enterprises felt maximum impact – those with over 1,000 employees or $500 million ARR reported average losses of nearly $500,000 per outage, and 8% said the hit exceeded $1 million.
In an AI-powered, always-on economy, minutes of downtime cascade into failed payments, frozen dashboards, and dark ad networks. That’s why we’re calling a higher standard for resilience “table stakes.” If your systems can’t guarantee business continuity without data loss, they’re not production-ready.
For over a decade, Cockroach Labs has helped organizations move from brittle, region-bound architectures to globally distributed data systems that confidently span regions and clouds. One example is Form3, the cloud-native payments platform used by major banks across Europe. Form3’s multi-cloud CockroachDB deployment keeps transactions flowing, even when a cloud provider goes dark. For them, 24/7 availability isn’t a target; it’s a requirement.
Your customers expect instant, intelligent, and uninterrupted experiences. That’s why resilience has become a major competitive edge. Performance under Adversity underscores CockroachDB’s commitment to resilient data infrastructure, even under the most challenging conditions.
How can data architects design beyond the default?
There’s a common thread among enterprises that weathered AWS’ outage: They anticipated failure. The pivot from reacting to preparing is a key mindset shift that’s reshaping executive priorities. Forward-looking companies are even appointing Chief Resilience Officers, signaling that fault tolerance has been elevated from engineering to the boardroom.
Data resilience best practices that enterprises should apply:
Design for failure. Assume systems and services will fail at some point.
Treat each region and cloud provider as a failure domain. Assume one will suddenly vanish.
Validate independence. Don’t let control planes or shared DNS become hidden couplings.
Automate failover. Manual recovery is too slow when millions of sessions are in limbo - focus on continuous availability.
Prioritize correctness. True resilience means replicas stay in sync and transactions complete correctly.
Test regularly. Chaos testing and latency drills build confidence and preparedness.
For teams determined to make outages a non-event, our Resilience page walks through architectural patterns that keep systems online. It provides a step-by-step guide for replicating our Performance under Adversity benchmark in your environment.
Ready for a higher standard of resilience?
Every outage is a solemn reminder: The internet is still surprisingly fragile. Five 9’s durability is a design choice, not a default setting. The question for architects isn’t if a cloud or region failure happens, but how systems respond when it does. Will your customers overwhelm your support teams, or not even know there was an outage?
At Cockroach Labs, we believe the winners won’t be those who recover fastest. They’ll be the ones who never crash.
That’s the north star guiding our new series, Outages Observer. Join Cockroach Labs as we explore what global disruptions reveal about data resilience, and how modern systems must evolve to meet a constant uptime world.
How will your enterprise perform under adversity? Visit here to talk to an expert.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
David Weiss is Senior Technical Content Marketer for Cockroach Labs. In addition to data, his deep content portfolio includes cloud, SaaS, cybersecurity, and crypto/blockchain.


