
If your company has a global customer base, you’ll likely be building an application for users in different areas across the world. Deploying the application in just a single region can make high latencies a serious problem for users located far from the application’s deployment region. Latency can dramatically affect user experience, and it can also lead to more serious problems with data integrity, like transaction contention. As a result, limiting latency is among the top priorities for global application developers.
In this blog, we walk you through a low-latency multi-region application that we built and deployed for MovR, a fictional vehicle-sharing company with a growing user base. The MovR application is a Flask web application, connected to a CockroachDB cluster with SQLAlchemy. We deployed the application in multiple regions across the US and Europe, using Google Kubernetes Engine, with some additional Google Cloud Services for load balancing, ingress, and domain hosting. For the database, we used a multi-region CockroachDB Dedicated deployment on GCP. The application source code is available on GitHub, and an end-to-end tutorial for developing and deploying the application is available on our documentation website.
Latency in Global Applications
MovR provides a platform for people to share vehicles. Their customers can register vehicles and take rides in supported cities. MovR is based in New York City, but they want to open up their service to several other cities in the US and in Europe. As they go global, they start to worry about the latency on requests coming to their application from different parts of the world. If the MovR application and database are deployed in a single region on the east coast, latency can be a serious problem for users located in supported cities that are far from the east-coast deployment region, like Los Angeles or Rome.
Broadly speaking, when a client makes a request to an application, there are two different types of latency on the request that can be improved with a well-designed deployment strategy:
Database latency, which we define as the time required for applications to complete requests to a database and receive responses from the database.
Application latency, which we define as the time required for clients (i.e., end users) to complete requests to the application and receive responses from the application.
In Reducing Multi-Region Latency with Follower Reads, we go into more detail about different types of latency and their respective impacts on performance. In this blog, we limit the discussion to these two general categories.
To limit database latency for MovR, we can deploy the database in multiple regions. We document a number of different database deployment configurations on our Topology Patterns documentation page. The geo-partitioned replicas topology pattern, the pattern we chose to use for MovR, constrains data to the database deployments closest to the regions from which a client makes requests. This reduces the distance requests must travel between application deployments and database deployments that are located in proximity.
To limit application latency, we can deploy the application in multiple regions, and ensure that each application deployment communicates with the database deployment closest to it. We also need to make sure that client requests are routed to the application deployment closest to the client. The application needs to be able to determine the location from which it receives its requests. Database operations in the application can then use the client’s location to query the correct (i.e., closest) partitions of data.
The Database Schema
It helps to start thinking about geo-partitioning as early as possible, especially when designing the database schema. For the purposes of this example application, we decided to go with a more simplified version of the movr database that is included in the cockroach binary.
The schema for this application’s database has the following tables:
usersvehiclesrides
Here’s a diagram of the database schema, generated with DBeaver:
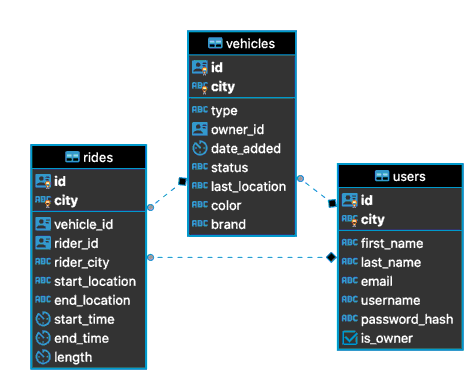
Each of these tables contains a city column in its primary index. This column tells us where a particular user, vehicle, or ride is located. We can partition each table based on these city values, mapping a subset of cities to a deployment region (e.g., Los Angeles, San Francisco, and Seattle to US-West) in the partition definitions. Then we can define zone configurations that constrain each partition to the regional deployments.
Although we chose to use cities to signify the location column on which to partition, many applications could benefit from a database with location columns at a higher level of abstraction, like region, province, or country.
The statements for creating and geo-partitioning these tables are all included in dbinit.sql, in the movr-flask project.
The Application
The application stack consists of the following components:
Python class definitions that map to the tables in the
movrdatabase.Functions that wrap database read and write transactions.
A backend API that defines the application's connection to the database.
A Flask server that handles requests from clients.
Bootstrapped HTML templates that the Flask server can render into web pages.
Because we are mainly concerned with how our multi-region application will communicate with a multi-region deployment of CockroachDB, let’s focus on the Python classes, functions, and the “backend API”.
First, let’s look at a class definition that maps to a table in the database. Here is the definition for the Vehicle class, defined in the models.py file:
class Vehicle(Base):
__tablename__ = 'vehicles'
id = Column(UUID)
city = Column(String)
type = Column(String)
owner_id = Column(UUID, ForeignKey('users.id'))
date_added = Column(DATE, default=datetime.date.today)
status = Column(String)
last_location = Column(String)
color = Column(String)
brand = Column(String)
PrimaryKeyConstraint(city, id)
def __repr__(self):
return "<Vehicle(city='{0}', id='{1}', type='{2}', status='{3}')>".format(
self.city, self.id, self.type, self.status)
This class maps to the vehicles table in the movr database. Each attribute of the class maps to a database object of the table, like a column or a constraint. The data types passed to each Column() constructor correspond to CockroachDB data types. When defining primary key columns, it's best practice to use UUIDs rather than sequential keys. Adding a location column to the primary key allows us to split the data up based on the location information of specific rows. Note that the PrimaryKeyConstraint is on the city and id columns, which maps to the composite primary key constraint in the vehicles table.
Next, let’s look at a transaction function. This type of function defines a group of database operations that the ORM converts to SQL transactions that are sent to a running CockroachDB cluster for execution. Here is the transaction function definition for start_ride_txn, defined in the transactions.py file:
def start_ride_txn(session, city, rider_id, rider_city, vehicle_id):
v = session.query(Vehicle).filter(Vehicle.city == city,
Vehicle.id == vehicle_id).first()
r = Ride(
city=city,
id=str(
uuid.uuid4()),
rider_id=rider_id,
rider_city=rider_city,
vehicle_id=vehicle_id,
start_location=v.last_location,
start_time=datetime.datetime.now(
datetime.timezone.utc))
session.add(r)
v.status = "unavailable"
This function takes some input passed from the frontend, and calls a couple SQLAlchemy Session functions, using that input. session.query() reads rows in the table, and session.add() inserts rows.
Note that the session.query() call first filters on city. The tables and indexes defined in dbinit.sql are partitioned on city values, and those partitions are constrained to a particular deployment region. Because these partitions are constrained to a single region per the geo-partitioned replicas topology pattern, all operations filtered on a city value only query a single partition of data, geographically located near that city.
When you write SQLAlchemy operations for CockroachDB, you need to wrap the operations in a wrapper function that is included with the CockroachDB SQLAlchemy dialect, called run_transaction(). run_transaction() takes a transaction function (like start_ride_txn) as a callback, creates a new database session, and then executes the callback using the new session. This ensures that all database operations written with the ORM do not violate CockroachDB transactional guarantees.
Finally, let’s look at the “backend API” functions. The application frontend calls these functions, and then these functions call run_transaction() to make changes to the database. Here is the definition for start_ride, defined in the movr.py file:
def start_ride(self, city, rider_id, rider_city, vehicle_id):
return run_transaction(
sessionmaker(
bind=self.engine), lambda session: start_ride_txn(
session, city, rider_id, rider_city, vehicle_id))
When a user hits “Start ride” in the application’s web UI, the request gets routed to start_ride(). start_ride() calls run_transaction(), with start_ride_txn() as the callback function, to update a row of the vehicles table and insert a new row into the rides table. Again, note that this only reads and writes to the partition closest to the city passed down to the transaction function.
We don’t go into much detail about the other components of the application in this blog. For more information about the application, see the Develop a Multi-Region Application section of the end-to-end MovR tutorial.
Deployment
To deploy the database, it’s easiest to use CockroachDB Dedicated, our managed database service. To get a multi-region CockroachDB Dedicated deployment, sign up for CockroachDB Dedicated, and then request the regions and the cloud service provider that you want.* For our demo deployment of the MovR application, we used a multi-region CockroachDB Dedicated deployment on GCP.
After the CockroachDB Dedicated team has deployed the multi-region cluster, we can access everything we need to connect to the cluster from the application (a connection string, a certificate, and the credentials for the authorized user) from the CockroachDB Dedicated console. For more detailed instructions about connecting to a CockroachDB Dedicated cluster, see Connect to Your CockroachDB Dedicated Cluster.
From the CockroachDB Dedicated console, we can also pull up the CockroachDB Admin UI, to monitor and inspect the database. From the “Metrics” page, we can see the performance of nodes in the cluster:

From the “Database” page, we can see the table, index, and partition definitions for the rides table:

CockroachDB Dedicated abstracts the complexity of orchestrating a multi-node, distributed database deployment across multiple regions. It’s virtually cloud-agnostic. Application deployment, on the other hand, heavily depends on the cloud provider, making things a little trickier.
For the MovR application deployment, we containerized the application project, deployed it to multiple clusters using Google Kubernetes Engine, and then set up a multi-cluster ingress using Google’s kubemci tool. An important step in setting up a multi-region application is making sure that the client location information is passed on to the application server. Fortunately, GCP allows you to define custom headers that you can forward to the application. Other web services likely allow for header forwarding, but you will probably need to reverse-geolocate an IP address (usually passed in the header X-Forwarded-For) with client-side logic.
For more details about the database and application deployments, check out the Deploy a Multi-Region Web Application of the MovR tutorial, or the README in the movr-flask project. To make things easier for development and debugging, we also provide a local database and application deployment workflow.
Single-Region Deployment vs. Multi-Region Deployment
To roughly measure the latency gains from our multi-region deployment, we compared the differences in latency on a subset of SQL requests between the single-region application and database deployment and the multi-region application and database deployment, as reported by the CockroachDB Admin UI.
Using a proxy service, we navigated to the MovR website from Rome, and performed the following tasks:
Signed up (
INSERT INTO users)Logged in (
SELECT FROM users)Viewed available vehicles (
SELECT FROM vehicles)Added vehicle (
INSERT INTO vehicles,UPDATE users)Started ride (
INSERT INTO rides,UPDATE vehicles)Ended ride (
INSERT INTO rides)Viewed rides (
SELECT from rides)Logged out
For the single-region deployment, we created a single-region CockroachDB Dedicated cluster on GCP in the US-East region. We then re-deployed the application, using GKE and GCP, in just the US-East region.
Here are the results in the single region case:
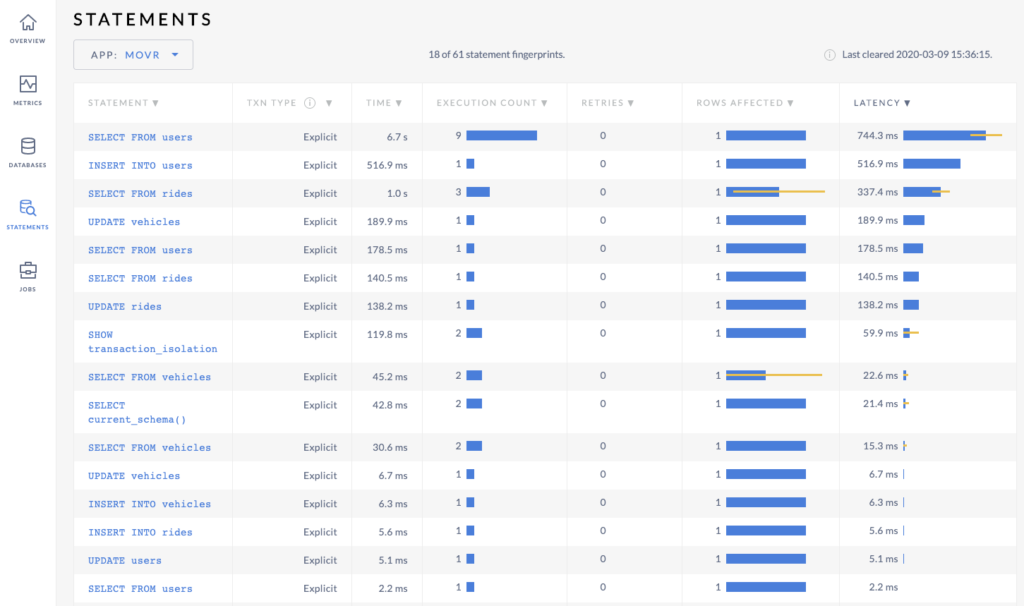
Latencies were, on average, around 150ms.
Here are the multi-region results:
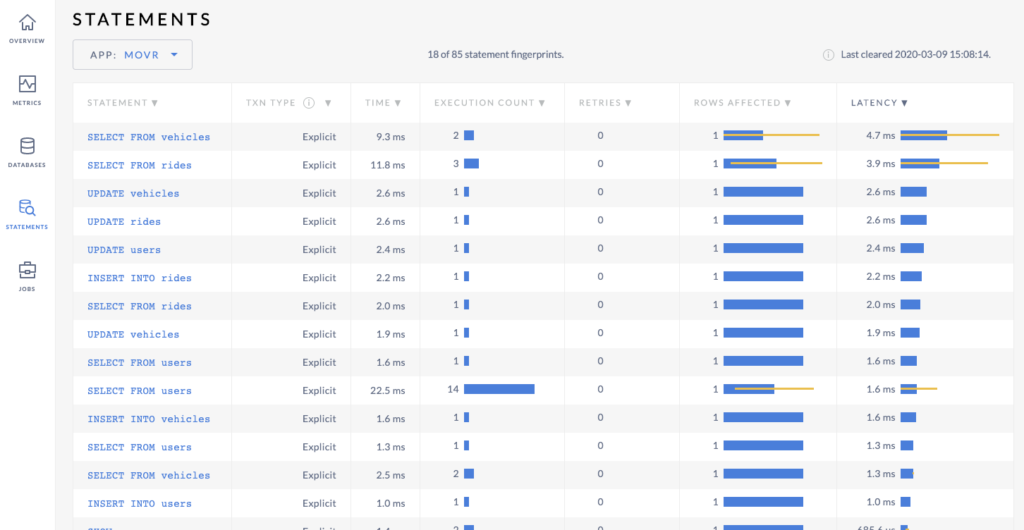
On average, the latencies on these requests were under 2.5ms. Optimizing deployments for latency reduced the average latency on these client-database requests by over 60x!
Our latency comparison exercise here does not explore higher-throughput scenarios. There would likely be many more than just a single client making requests to the application and database. We also do not explore hybrid deployment configurations (for example, a single-region database deployment and multi-region application deployment), or cross-cloud configurations (for example, CockroachDB Dedicated deployed on AWS and the application deployed using GCP services). In the Reducing Multi-Region Latency with Follower Reads blog post, we take a more rigorous approach to analyzing the latency improvements from different multi-region deployments.
Conclusion
Latency can be a big problem for global applications. CockroachDB’s multi-region features, geo-partitioning in particular, can help limit latency in global applications. To demonstrate these features in the context of a global application, we built and deployed an application on CockroachDB across multiple regions in the US and Europe. CockroachDB Dedicated made database deployment easy, but deploying the application wasn’t as straightforward.
The example application code and SQL schema statements are publicly available on GitHub. We encourage you to fork the movr-flask repo and go through the end-to-end Develop and Deploy a Multi-Region Web Application tutorial. Also, you can interact with a deployed version of the MovR app by navigating to https://movr.cloud.
*Currently, multi-region CockroachDB Dedicated deployments are not available through the CockroachDB Dedicated self-service console. To set up a multi-region CockroachDB Dedicated deployment, contact us at sales@cockroachlabs.com.


