

Internet of Things (IoT) and microservices-style applications need a database that can handle requirements such as fluctuating number of client connections, unpredictable workloads, and bursty throughputs. Traditional single-node databases handle these requirements by reducing latency to improve throughput. However, for modern distributed databases such as CockroachDB, the optimal approach to handle these requirements is to use multi-row SQL Data Manipulation Language (DML) and parallel processing.
Multi-row DMLs provide an order-of-magnitude improvement in throughput performance as compared with equivalent single-row DMLs, which is why databases such as Oracle, MySQL, and Postgres widely support multi-row DMLs. CockroachDB has supported multi-row DMLs since the 1.0. This blog post discusses how to use multi-row DMLs, the performance benefits of multi-row DMLs over single-row DMLs, and the effects of compounding database and application parallelism in single-node vs. distributed databases.
When to Use Multi-Row DML Syntax
The following table shows examples of single-row and multi-row DMLs for INSERT, UPSERT, and DELETE statements. The number of rows specified in the DML is called the “batch size”. Single-row DML always has batch size of 1.

Example: Tabulation Service
Using multi-row DMLs improves CockroachDB’s throughput dramatically. To understand why, let’s consider the example of a tabulation service, say for financial transactions, voting mechanisms, or ecommerce apps, and see how the service works with CockroachDB.
A tabulation service processes events generated by a fluctuating number of clients and persists the events (that is, saves the events) into a database. Because the rate of event generation is higher than the rate at which the events can be persisted to the database, a mismatch occurs between event generation and persistence. This mismatch can create throughput impedance mismatch (or to put it simply, it can cause throughput bottleneck). In order to compensate for the mismatch, the events are placed in a queue, as shown in Figure 1.

Figure 1
The client retrieves the event from the queue, processes it, and persists it to the database using the basic INSERT DML.
Insert into x values (1,’A’);
The client then connects to CockroachDB through a gateway process and sends the INSERT DML. If you have followed CockroachDB over the years, you may be familiar with our approach of mapping SQL onto a KV keyspace. The gateway sends the KV request to the node that contains the KV range.
CockroachDB Single-row DML
Now let’s assume a heavy impedance mismatch that caused 9 events to be queued up. The client retrieves and processes one event at a time from the queue. The single-row DML inserts nine separate statements as follows:
Insert into x values (1,’A’);
Insert into x values (2,’B’);
Insert into x values (3,’C’);
Insert into x values (4,’D’);
Insert into x values (5,’E’);
Insert into x values (6,’F’);
Insert into x values (7,’G’);
Insert into x values (8,’H’);
Insert into x values (9,’I’);
Assume there are 3 CockroachDB nodes, where the KV node with ranges 1 to 3 contains keys 1 through 3, the KV node with ranges 4 to 5 contains keys 4 through 5, and the KV node with range 7 to 9 contains keys 7 through 9. CockroachDB receives a series of DMLs and processes them one at a time. The gateway receives the statement, which is then sent to the KV node. The KV node receives and executes the single statement with one row. When a statement touches a single range, CockroachDB performs fast-path commit directly on the KV node. Figure 2 shows the sequence diagram for the operation, which clearly shows that executing each single-row statement causes other events to wait in the queue.

Figure 2
CockroachDB Multi-row DML
Now let’s consider how the same scenario works with multi-row DML. With multi-row DML, The client retrieves all events from the queue, and inserts the nine values in a single statement as shown below.
Insert into x values (1,’A’),(2,’B’),(3,’C’),(4,’D’),(5,’E’),(6,’F’),(7,’G’),(8,’H’),(9,’I’)
The sequence diagram in Figure 3 shows that the initial client-to-gateway communication is the same as the single-row DML. The gateway creates three execution paths based on the three KV nodes. In parallel, each of the KV nodes receives and executes the single statement with three rows. Once the KV nodes complete their operation, the gateway performs the CockroachDB equivalent of a two-phase commit by writing COMMIT intent in the transaction record in the first KV range. As evident from Figures 2 and 3, the multi-row DML shows considerable reduction in execution steps over multiple single-row DMLs.
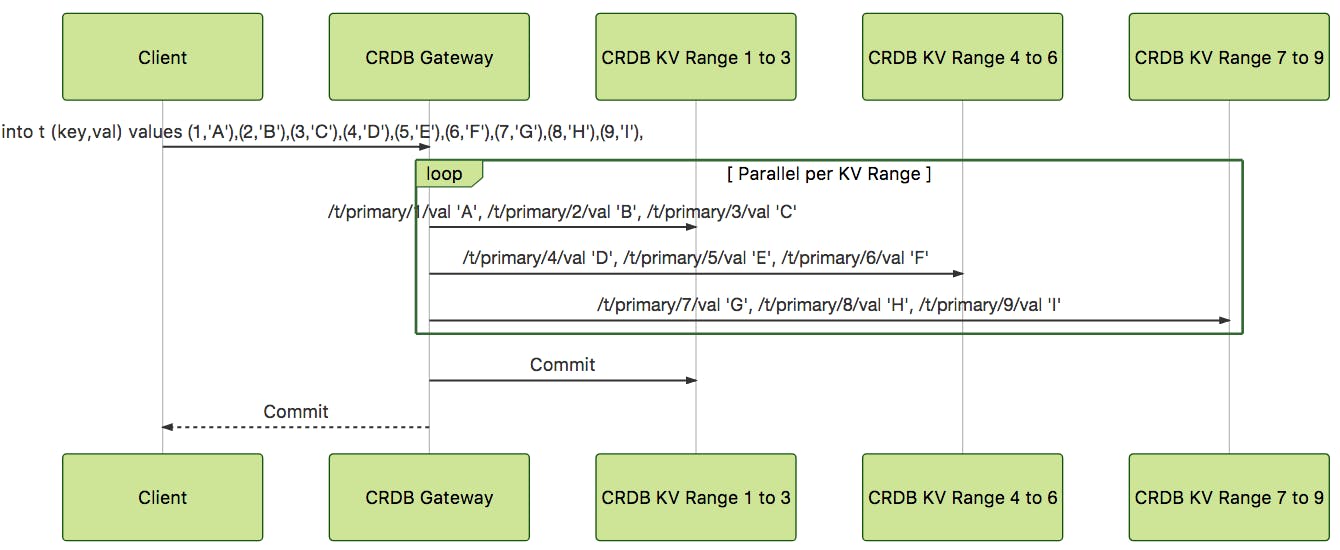
Figure 3
Potential Throughput Improvement
Let’s compare the number of occurrences for single-row and multi-row execution steps required to insert the 9 events into CockroachDB.
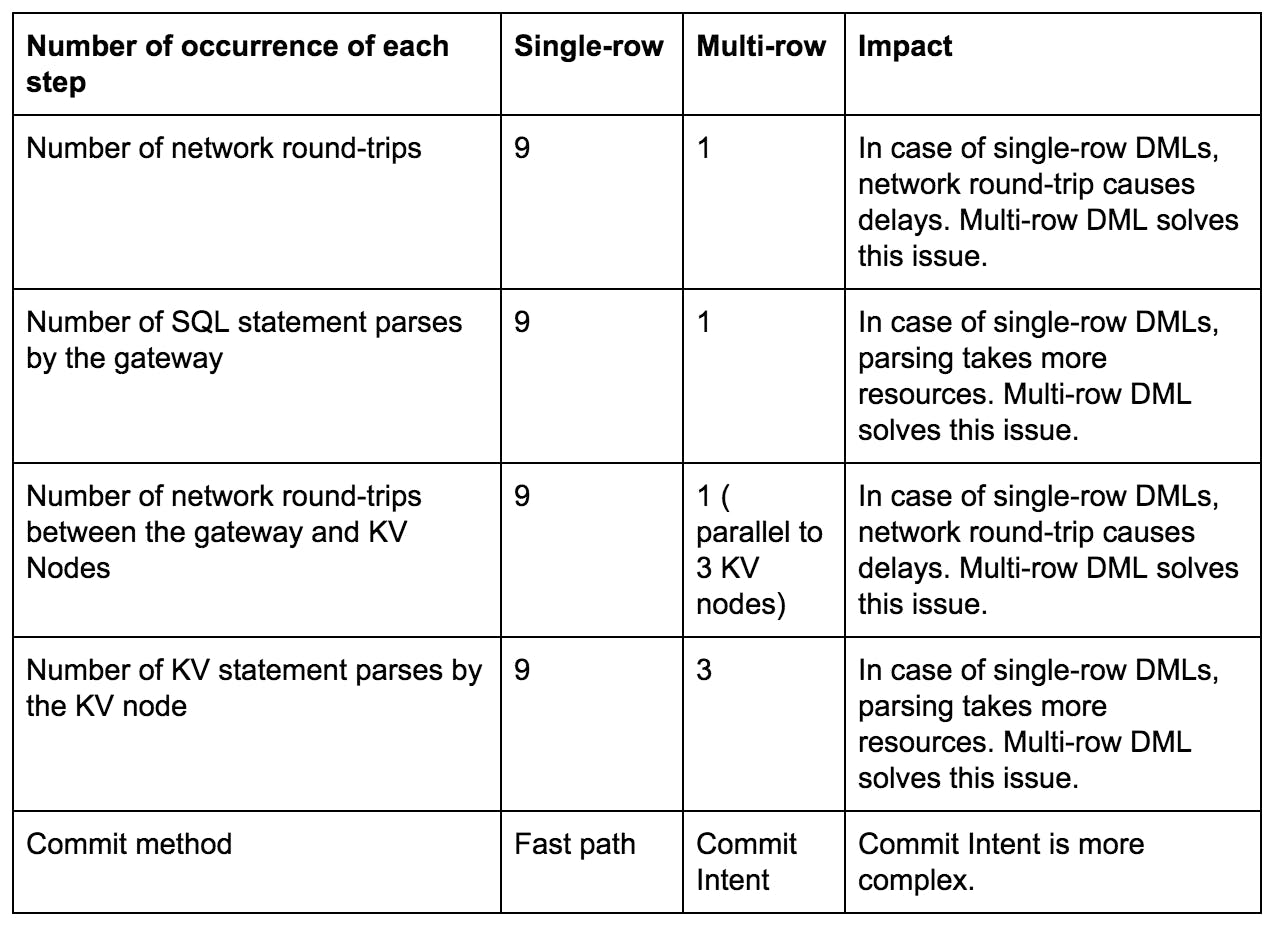
As seen from the table, multi-row DML requires fewer network round-trips and statement parses that should result in better throughput with less resource consumption. However, the impact of multi-row DML’s Commit Intent is unknown. Let’s figure out the impact of the Commit Intent on performance.
Actual Throughput Improvement
To measure the throughput improvement, we used an open-source load generator called Rand to execute INSERT DMLs into TPC-H lineitem table on a 4-node CockroachDB cluster. The following graph plots relative performance improvement by varying the batch size on the x-axis. The baseline measurement uses a batch size of 1 (single row) with concurrency of 2 -- that is two separate threads running independently.
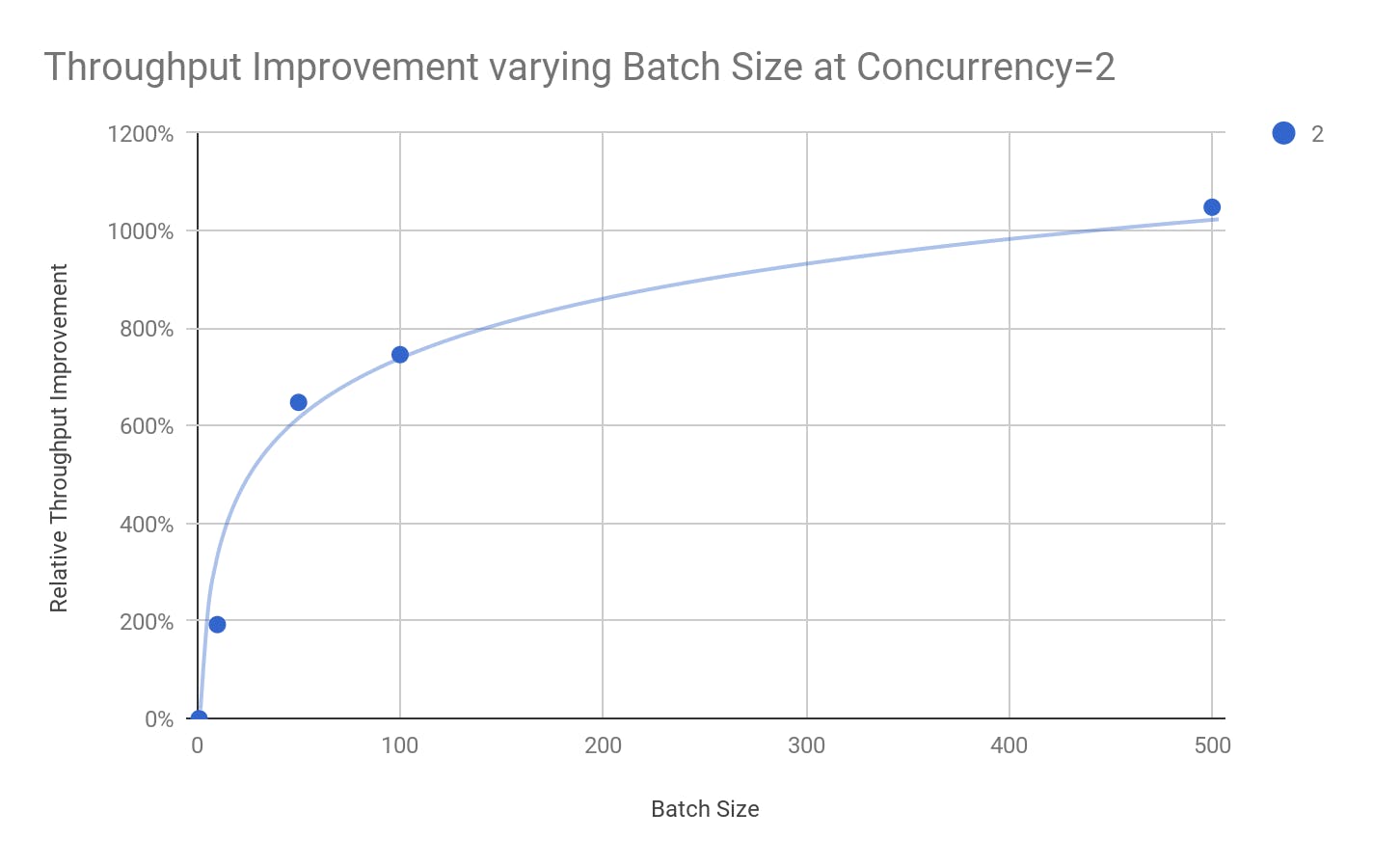
As the graph shows, increasing the batch size increased the throughput as expected. A batch size of 10 yielded 2x the throughput, and batch size of 50 yielded close to 7x throughput respectively.
However, the graph also shows an inflection, a point of diminishing return, at a batch size of 100. This inflection point depends on the number of KV nodes, network latency, and the workload. Generally, the throughput improvement will be higher with more servers, higher network latency, and bigger batch size.
Database Parallelism and Application Parallelism
A common practice to improve performance even further is to compound parallelism from application and database levels. But with single-instance databases, the resources are limited, so over-parallelizing can actually decrease performance.
A system can context switch among many parallel workloads, which is normal for regular workloads. But when the system resources are fixed (as is the case with single-node databases) and parallelism is increased beyond the limits, the system will spend more time on the context switch rather than running the workload. The excessive context switch leads to decrease in throughput. Therefore, increasing the application concurrency with database parallelism should move the inflection point to the left on the graph.
To understand the impact of over-parallelizing in single-node databases, let’s use CockroachDB to artificially create the limitations that single-instance databases face with limited resources. In the previous section, we saw that CockroachDB multi-row automatically parallelized execution to the same degree as the number of KV nodes. Our example test also used an application concurrency of 2. The following graph shows a second test with an application concurrency of 4. Doubling the application concurrency doubles the throughput at batch size of 10. However, as the batch size is increased to 50, we encounter the point of diminishing returns. At batch size of 100, the throughput is actually below that of batch size 50.
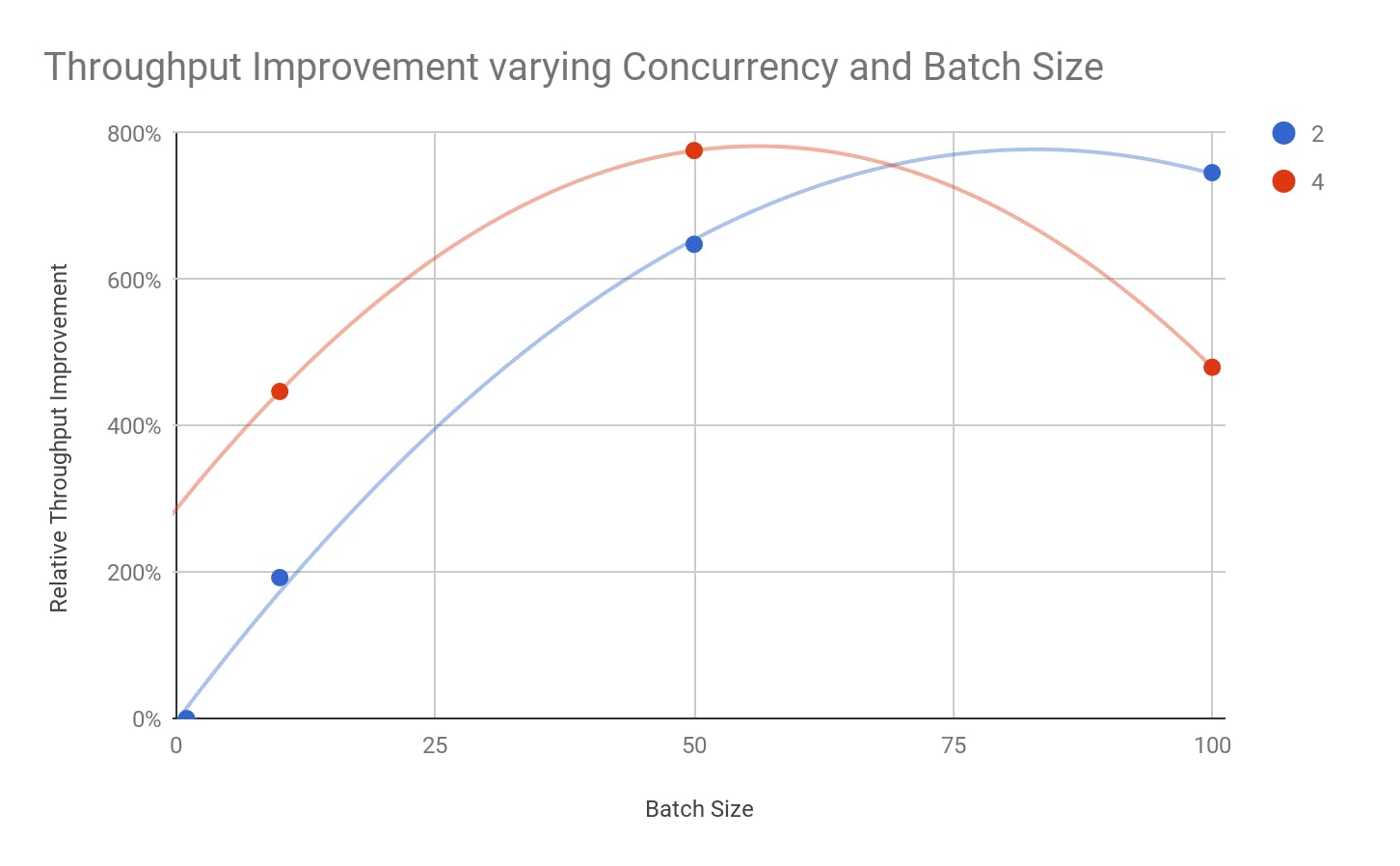
In this example, we deliberately limited the number of nodes to 4 to artificially create the limitations that single instance databases face. But CockroachDB being a distributed database, we could easily scale the number of nodes, which would help us overcome these limitations.
The second test shows that if your database is not scalable, then you need careful upfront planning to avoid over-parallelization. This planning, often called sizing and capacity planning, is complex and time consuming. CockroachDB, on the other hand, is a scalable database that handles the complexity so you don’t have to. It enables your IoT applications and microservices to safely handle unpredictability concurrency.
Summary
Multi-row DML improves throughput and reduces resource consumption. CockroachDB automatically parallelizes the multi-row DML processing, and the empirical data that the Rand tool test shows that increasing the batch size results in better throughput. We also saw how databases that are not scalable can face excessive context-switching when aggressive application parallelism is used in combination multirow DML, but because CockroachDB is scalable database, the multi-row DMLs can safely be used to improve throughput. Future blog posts will discuss scalability and its benefits in further detail.
Illustration by Lea Heinrich


