


In this post Rob and I explain how we built Silo, a fully functioning multi-region Next.js application combining CockroachDB multi-region serverless and a multi-region Node.js (Lambda) API backed by a Geographically aware Route 53 Hosted Zone. Both the API and CockroachDB have been deployed to AWS. The Next.js app has been deployed using Vercel.
There are a number of reasons why you’d want to choose a multi-region strategy; to optimize latency, maintain high availability and, in some cases, to comply with regional regulations. But, rather than tell you about the benefits, I’d like to show you.
You can preview the App and view the src code using the links below.
🚀 Preview
⚙️ GitHub Repository / Next.js Application
⚙️ GitHub Repository / Node.js API
Creating Artwork using Silo
Silo invites site visitors from all over the world to “sign in” and create their own unique digital artwork.
… but we’ve been sneaky.
In the App, you the user, can create artwork using both US-centric images and colors and EU-centric images and colors, as well as applying some finishing touches that apply to artwork created in both regions such as pattern overlays, the position of the Cockroach logo and a theme for the Silo logo.
Saving Artwork using Silo
When you save however, we split this data and store some of it in the US, us-east-1, (which is replicated in us-west-2) and some of it in the EU, eu-central-1.
When you preview your artwork or visit the gallery you’ll only be able to see artwork saved to your local region. Only during the creation process will you be able to see artwork created in both regions, intrigued? Read on.
Here’s a screenshot of the App where you can create and save artwork using US-centric images and colors which will be stored in the US.

If you scroll down a little further in the App, you’ll also be able to create and save artwork using EU-centric images and colors which will be stored in Europe. Scroll down a little further again and you’ll be able to apply some finishing touches which are saved to both regions and made globally available.

It’s one database!
It’s worth noting that I’ve experimented with CockroachDB multi-region instances, deployments and clusters once before, you can read about that project on The New Stack: The Distance from Data to You in Edge Computing. I had a number of readers reach out with comments relating to the difficulties of maintaining multiple databases in multiple regions, but that project didn’t have multiple databases in multiple regions, and this project doesn’t either.
The database used in both Edge and Silo is a single logical CockroachDB serverless instance.
I use one connection string to query one database that contains two tables, spread across multiple physical geographical locations. That’s it!
But, before I move on to explaining CockroachDB multi-region, I’ll quickly explain the problem with single regions.
The problem with single regions
Here’s an example of a common architectural setup where both the server and the database have been deployed to a single region, us-east-1.

The round trip for this journey from my location in the UK to the server, then to the database, then back to me would be approximately ~3,700 mi / ~5,900 km.
Understandably, this transatlantic journey won’t be a problem for users based in the US but, as you’d imagine, many companies have users on both sides of the Atlantic and really, you need to please them all. To address this, the general idea would be to bring the database closer to the user.
Bringing the database closer to the user
To remove the potentially unnecessary transatlantic journey my request needs to make, CockroachDB can be deployed to multiple regions. But, will moving the database closer to the user solve the problem?
The short answer is sadly, no. By moving the database alone, in some cases, you might actually be increasing both the distance traveled and the latency.
Here’s an example of CockroachDB deployed to three geographical locations, two are on the wrong side of the Atlantic for me, but one is within Europe and thus, much closer to my location in the UK.
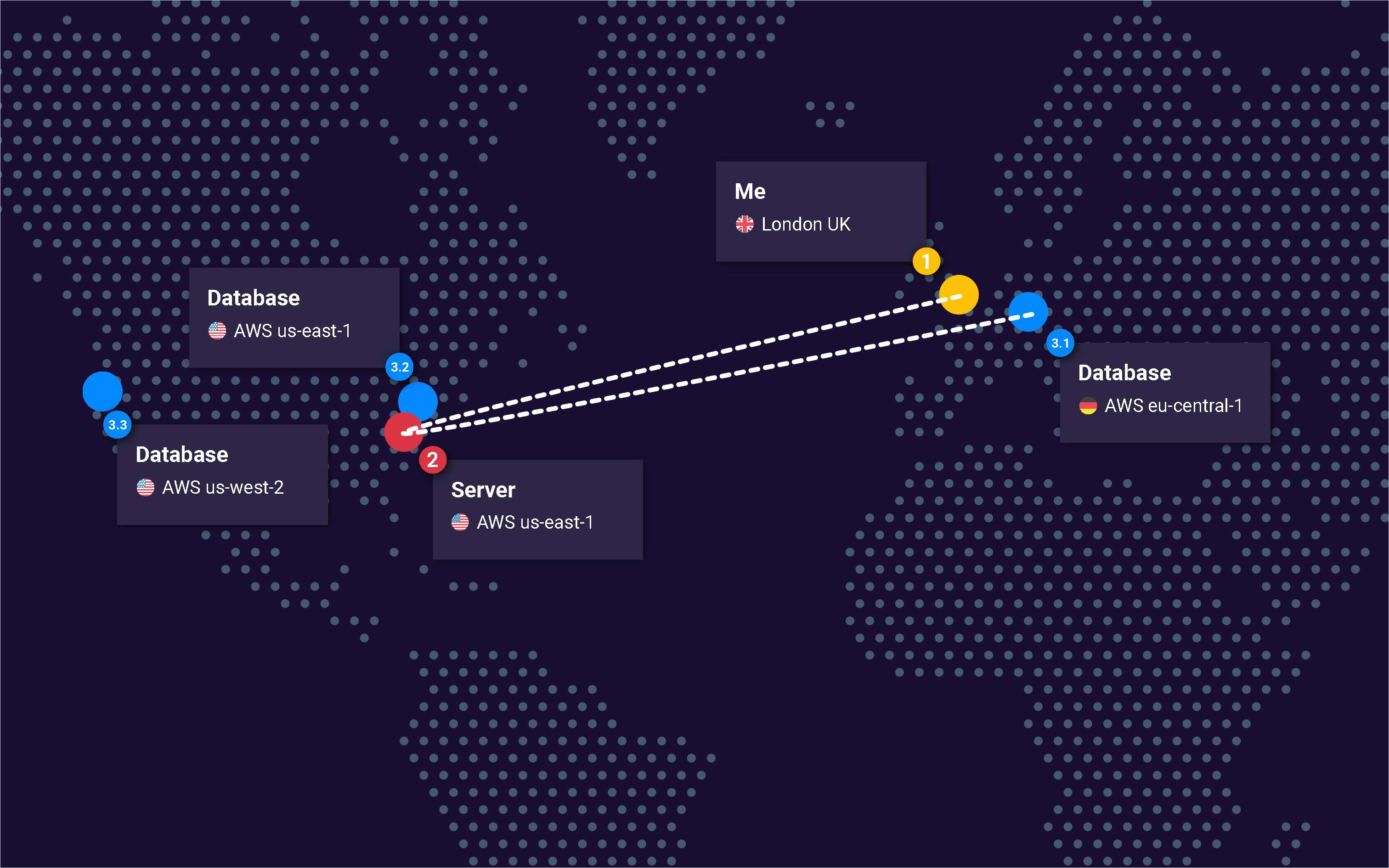
The total round trip for this journey is approximately ~7,700 mi / ~12,400 km.
Blast! By bringing only the database closer to me, the distance traveled here is actually ~47% further than it was when the database was located in the US. That’s almost twice the distance and likely, twice the latency.
This happens because my request still needs to travel over the Atlantic via the server deployed in us-east-1. It should become clear now that to make the most of multi-region database architecture you’ll need to employ a similar multi-region strategy for your servers.
I liken this pairing to chip and PIN. Whilst individually these technologies are fantastic, they only really work when they’re used together. Don’t believe me? Here’s my PIN, 4950, it’s no good without the card!
Maximize on Multi-Region
So really then, for end users to truly benefit from a multi-region database you need the full complement.
Here’s how I architected the Silo App. I’ve deployed both the servers and database to the same geographical locations.

With this setup the total round trip for my journey is approximately ~400 mi / ~630 km.
In this example I’ve reduced the total distance by ~95%!
However, we’re not quite in the clear yet. I’d now like to explain how requests from the end user are appropriately routed via servers to yield such results.
AWS Route 53 Hosted Zones
Apologies in advance, I’m now going to talk about DNS. For those who don’t know, DNS is the magical method of turning IP addresses into human readable URLs, but it can do so much more.
DNS A Record Type
Using an A Record type in the Route 53 Hosted Zone I’m able to differentiate between requests that were made from within Europe, and requests that were made outside of Europe.
If a request is deemed to originate from within Europe I route the traffic via an AWS API Gateway and on to a Node.js Lambda deployed in eu-central-1, which in turn can query data from a CockroachDB node, also deployed in eu-central-1.
Any requests from outside of Europe are routed using the default A Record which routes traffic via an API Gateway and on to a Node.js Lambda deployed in us-east-1, which in turn can query data from a CockroachDB node also located in us-east-1 (or us-west-2 if there’s an outage)
Here’s a screenshot of the DNS I set up for the Silo App.
DNS Geolocation aware DNS A Record.
Region and Lambda ARN alias.
Request location.

The default A Record (which deals with any requests outside of Europe) is the same, but it points to the API Gateway/Lambda deployed to us-east-1.
DNS Routing Example
To show you what that means, here’s the default API endpoint: https://api.crl-silo.net/
Depending on where you are in the world (inside, or outside of Europe) you’ll see one of the two responses below.
The details in the response will show you which region your request was routed through.
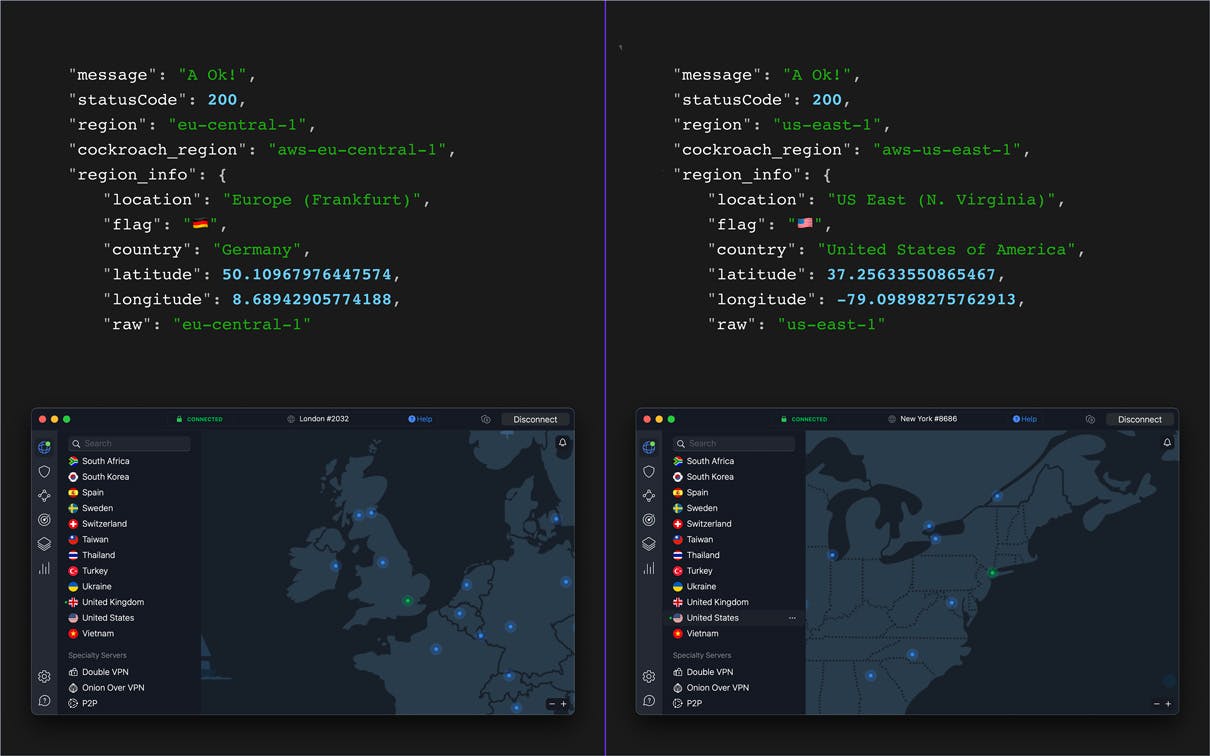
You’ll notice among the details above there’s an object key called region, this is actually the “key” to this entire application!
As I mentioned earlier, CockroachDB is a single logical instance, but it exists in multiple regions. My AWS Lambdas work in a similar way, they are exactly the same, but are deployed to different regions.
So why are the responses different?
process.env.AWS_REGION
Here’s a code snippet from the Lambda that generated the above responses.
module.exports.handler = async () => {
return {
statusCode: 200,
headers: headers,
body: JSON.stringify({
message: 'A Ok!',
statusCode: 200,
region: process.env.AWS_REGION,
cockroach_region: `aws-${process.env.AWS_REGION}`,
region_info: fromProvider(process.env.AWS_REGION, 'AWS'
),
}),
};
};
You can see the src for this here: v1/index.js.
Depending on where the Lambda is invoked, us-east-1 or eu-central-1 will determine the value of the AWS_REGION environment variable.
I’ll explain how I’ve used this environment variable with CockroachDB next but, to help you understand how all these pieces fit together, here’s a more detailed diagram of the AWS configuration which shows you the “loop” that happens from when an end user makes a request, where the request is routed, and how data is returned back to the end user.

To ensure only the appropriate data is returned to each end user I use the AWS_REGION environment variable in a SQL WHERE clause to query CockroachDB to retrieve data relevant to the region. (This filtering logic could be wrapped into a VIEW, to which the Lambda user has SELECT permissions).
Environment Variable WHERE Clause
I used the environment variable available in the Lambda function in a SQL WHERE clause to select data based on geographical location.
On the Gallery page, (again, depending on where you are in the world), you’ll see one of the two screenshots below.
If you’re within Europe you’ll see artwork created using images of buildings from Europe and colors present in European country flags.
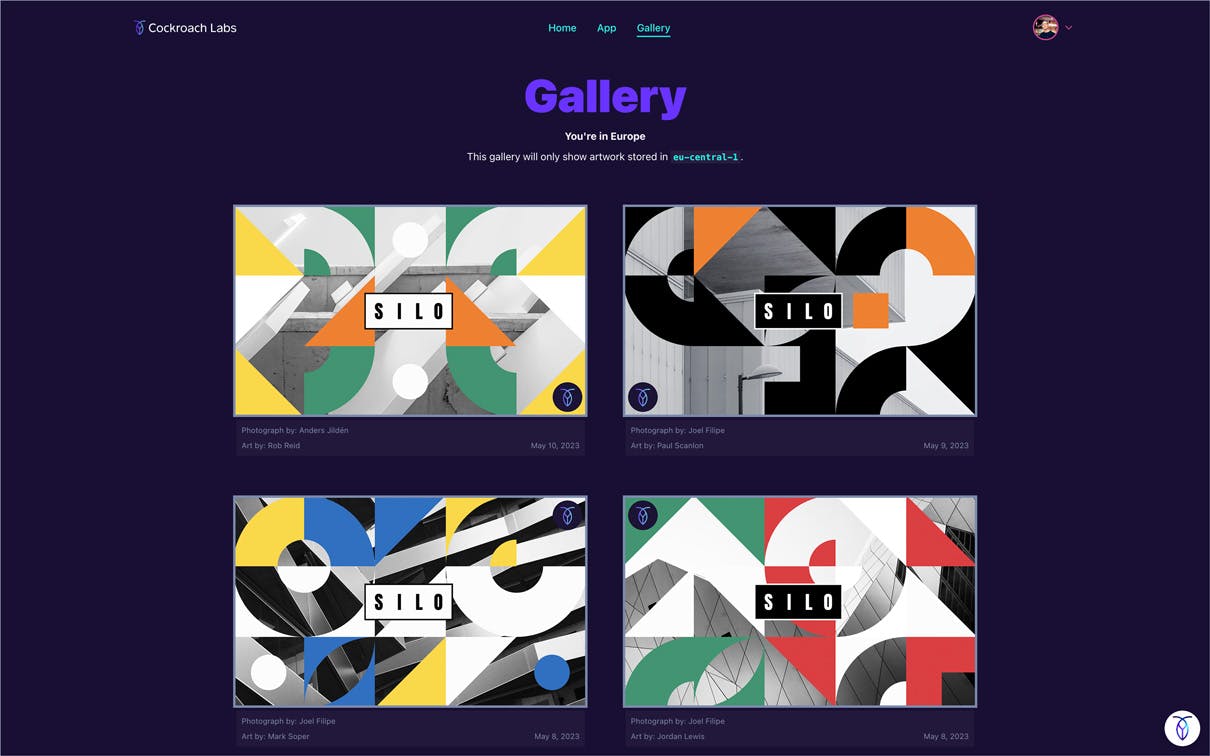
If you’re located anywhere else in the world, you’ll see artwork created using images of buildings from the US and colors present in the US flag.

The code used to make the request and the SQL used to query CockroachDB is exactly the same for both regions but the condition is created by leveraging the value of the environment variable.
Here’s a code snippet for the query responsible for returning the artwork seen on the Gallery page.
const region = `aws-${process.env.AWS_REGION}`;
try {
await client.query(
'SELECT l.user_id, l.values AS local_values, g.values
AS global_values
FROM art_local l
LEFT JOIN art_global g
ON l.user_id = g.user_id
WHERE region = $1',
[region]
);
} catch (error) {}
You can see the src for this code here: v1/gallery.js.
What is a WHERE clause
A WHERE clause is used to query data from a table within the database, it allows you to specify particulars rather than querying and returning absolutely everything, and by keeping the payload small, you’ll keep the response times snappy. CockroachDB nodes are location-aware, so by filtering for local data, CockroachDB knows that it only has to search for data from specific, local ranges.
I’m doing the same in Silo but, when you save your artwork, I add in the region which allows CockroachDB to determine which node, (within the single logical instance) should be used to store the data.
Data that is meant for the EU is given a region of aws-eu-central-1, and data that is meant for outside of the EU will be given a region of aws-us-east-1. The “aws” prefix is because CockroachDB is cloud native and can be deployed to AWS, GCP or Azure.
Now that each row of data in the table has been given a regional identifier, CockroachDB can be configured to pin that data to the appropriate region. This gives you an extremely high level of control over where your data resides — can your database do that?
Storing data in this way keeps latencies under control for users in all regions. Read/write latencies for EU data will be significantly reduced for EU end users and the same applies for users near the US regions. Pairing this configuration with a Lambda also deployed to that region means the total distance traveled by each request is much shorter. This all results in an application that feels much more snappier and hopefully, end users that are much happier.
I’ll now hand over to Rob to explain how he configured CockroachDB to automatically move data around the world depending on the region assigned when it was saved.
If you’d like to discuss any of the details in this post please feel free to find me on Twitter:
.What’s Going On Under the Hood?
Our demo app is backed by a single multi-region enabled CockroachDB serverless database, that is distributed globally, across AWS datacenters in Frankfurt (eu-central-1), North Virginia (eu-east-1), and Oregon (us-west-2). In this configuration, we can deliver data to users from datacenters that are close to them, and protect their data from leaking across continents.
Data can be grouped into one of two categories:
Regional - User-specific data that is location-sensitive
Global - Data that needs to be distributed globally to achieve low-latency read access from all locations
First, we’ll configure the database regions, based on the regions our cluster is deployed to:
ALTER DATABASE silo SET PRIMARY REGION "aws-us-east-1";
ALTER DATABASE silo ADD REGION "aws-us-west-2";
ALTER DATABASE silo ADD REGION "aws-eu-central-1";
Next, we’ll enable SUPER REGIONS and create a super region for the US and another for the EU. With no US super region, US data would be replicated into the EU and with no EU super region, EU data would be replicated into the US:
SET enable_super_regions = 'on';
ALTER DATABASE silo ADD SUPER REGION us\
VALUES "aws-us-east-1", "aws-us-west-2";
ALTER DATABASE silo ADD SUPER REGION eu\
VALUES "aws-eu-central-1";
With this configured, CockroachDB will not attempt to replicate US data into Europe or vice-versa. This reduces the number of replicas we’ll have for European data to 3, as there are only 3 nodes in the EU for this cluster. If you need European data to stay within Europe for your use cases, consider adding an additional European region and adding it to the eu super region to provide regional failure resilience in Europe.
Our demo is implemented across just two tables; let’s create them now.
art_local
The art_local table contains data that should reside within either the US or Europe. It uses the REGIONAL TABLEStopology pattern, and decides where a row should physically reside based on the value given to the “region” column. Note that the inclusion of a super_region column is not important to how the application works.
CREATE TABLE art_local (
user_id STRING NOT NULL,
username STRING NOT NULL,
region crdb_internal_region NOT VISIBLE NOT NULL,
last_updated TIMESTAMPTZ NOT NULL DEFAULT now():::TIMESTAMPTZ,
"values" JSONB NOT NULL,
super_region STRING NULL AS (regexp_extract(region::STRING, e'\\w+-(\\w+)-':::STRING)) STORED,
CONSTRAINT art_local_pkey PRIMARY KEY (region ASC, user_id ASC),
INDEX art_local_user_id_idx (user_id ASC)
) LOCALITY REGIONAL BY ROW AS region
art_global
The art_global table contains data that should be replicated across all regions in the database. This is achieved using the GLOBAL TABLES topology pattern.
CREATE TABLE public.art_global (
user_id STRING NOT NULL,
username STRING NOT NULL,
last_updated TIMESTAMPTZ NOT NULL DEFAULT now():::TIMESTAMPTZ,
"values" JSONB NOT NULL,
CONSTRAINT art_global_pkey PRIMARY KEY (user_id ASC)
) LOCALITY GLOBAL
Data in this table will be replicated across all three of our cluster regions, making reads from any location fast (at the cost of slower writes, owing to data needing to be written to multiple regions). Write speeds can be improved by lowering the --max-offset to 250ms but we’ve left this value as-is for the sake of the demo.
When a user visits the Gallery; we perform one query that joins the two tables. The Lambda that the user hits will perform the following query, passing process.env.AWS_REGION as an argument:
SELECT
l.user_id,
l.username,
l.region,
l.super_region,
l.last_updated,
l.values AS local_values,
g.values AS global_values
FROM art_local l
JOIN art_global g ON l.user_id = g.user_id
WHERE region = $1;
For EU users, we’ll provide aws-eu-central-1 as an argument for the query. This will return data with very low latency (ignoring Lambda cold-starts), whereas if that same European user were to request US data (e.g. aws-us-east-1), the query would have to fetch data from the US and would take closer to 115ms because of the increased network round trip time. For users across the rest of the world, we provide aws-us-east-1.
Joining the art_global table onto the art_local table, even though the table topology patterns are different, doesn’t cause any problems, as all
The data being requested for the joined table exists everywhere.
Reach out to me on Twitter
if you’d like to chat or find out more about our database setup!

