
When a CockroachDB node receives a SQL query, this is approximately what happens:

The pgwire module handles the communication with the client application, and receives the query from the client. The SQL text is analyzed and transformed into an Abstract Syntax Tree (AST). This is then further analyzed and transformed into a logical query plan which is a tree of relational operators like filter, render (project), join. Incidentally, the logical plan tree is the data reported by the EXPLAIN statement.
The logical plan is then handed up to a back-end layer in charge of executing the query and producing result rows to be sent back to the client.
There are two such back-ends in CockroachDB: a local execution engine and a distributed execution engine.
Local query processing
The local execution engine is able to execute SQL statements directly on the node that a client app is connected to. It processes queries mostly locally, on one node: any data it requires is read on other nodes in the cluster and copied onto the processing node to build the query results there.
The architecture of CockroachDB's local engine follows approximately that of the Volcano model, described by Goetz Graefe in 1993 (PDF link). From a software architect's perspective, each node in the logical query plan acts like a stateful iterator (e.g. what Python generators do): iterating over the root of the tree produces all the result rows, and at each node of the plan tree, one iteration will consume zero or more iterations of the nodes further in the tree. The leaves of the tree are table or index reader nodes, which issue KV lookup operations towards CockroachDB's distributed storage layer.
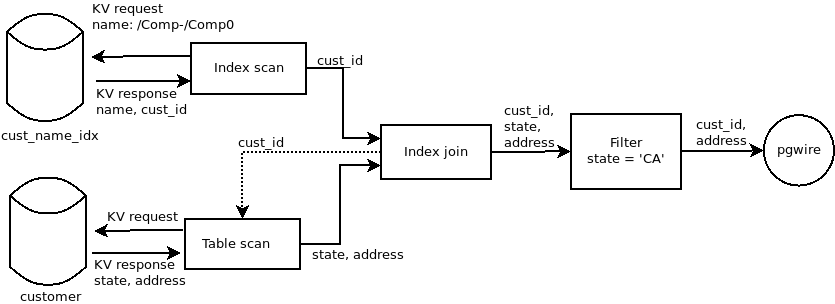
Example logical plan for:
SELECT cust_id, address FROM customer WHERE name LIKE 'Comp%' AND state = 'CA' Assuming primary key is cust_id and an index on customer(name).
From a code perspective, each relational operator is implemented as an iterator's "next" method; while a query runs, the tree of iterators is processed sequentially: each node's "next" method waits until the source nodes have completed their own "next" method call. From the outside, the query execution logic processes data and makes decisions (e.g. keep/remove a row, compute derived results) row by row. The processing is essentially sequential.
The main characteristic of this engine is that it is relatively simple.
The code for this engine can be reviewed and validated for correctness using only local reasoning; we (the CockroachDB developers) have come to trust it the most.
Also, because the processing is performed locally, it can deliver results very fast if all the data it needs is available locally (on the same node), and/or when there are only few rows to process from the source tables/indices.
Parallelized local processing for updates
A common pattern in client apps is to issue multiple INSERT or UPDATE (or UPSERT, or DELETE) statements in a row inside a single session/transaction. Meanwhile, data updates in CockroachDB necessarily last longer than with most other SQL engines, because of the mandatory network traffic needed for consensus. We found ourselves wondering: could we accelerate the processing of data writes by executing them in parallel? This way, despite the higher latency of single data-modifying statements, the overall latency of multiple such statements could be reduced.
This is, however, not trivial.
The standard SQL language, when viewed as an API between a client app and a database server, has an inconvenient property: it does not permit concurrent processing of multiple queries in parallel.
The designers of the SQL language, especially the dialect implemented by PostgreSQL and that CockroachDB has adopted, have specified that each SQL statement should operate "as if the previous statement has entirely completed." A SELECT statement following an INSERT, for example, must observe the data that has just been inserted. Furthermore, the SQL "API" or "protocol" is conversational: each statement may have a result, and the client app can observe that results before it decides which statement will be run next. For example UPDATE has a result too: the number of rows affected. A client can run UPDATE to update a row, and decide to issue INSERT if UPDATE reports 0 rows affected (the row doesn't exist).
These semantic properties of the SQL language are incredibly useful; they give a lot of control to client applications. However, the choice that was made to include these features in SQL has also, inadvertently, made automatic parallelization of SQL execution impossible.
What would automatic parallelization look like? This is a classic problem in computer science! At a sufficiently high level, every solution looks the same: the processing engine that receives instructions/operations/queries from an app must find which operations are functionally independent from the operations before and after them. If a client app / program says to the processing engine "Do A, then do B", and the processing engine can ascertain that B does not need any result produced by A, and A would not be influenced if B were to complete before it does, it can start B before A completes (presumably, at the same time), so that A and B execute in parallel. And of course, the result of each operation reported back to the app/program must appear as if they had executed sequentially.
With standard SQL, this is extremely hard to determine as soon as data-modifying statements are interleaved with SELECTs on the same table.
In particular, it is hard to parallelize SELECT with anything else, because in order to determine which rows are touched by a specific INSERT/UPDATE, and whether these rows are involved in a SELECT close by, the analysis required would amount to running these statements, and thus defeat parallelism upfront.
It is further impossible to parallelize multiple standard INSERT/DELETE/UPSERT/UPDATE statements, because each of these statements return the number of rows affected, or even data from these rows when a standard RETURNING clause is mentioned, and parallelization would cause these results to be influenced by parallel execution and break the semantic definition that the results must appear as if the statements execute in sequence.
This is why there is not much CockroachDB can do to parallelize data updates using standard SQL syntax.
However, when discussing this with some of our users who have a particular interest in write latencies, we found an agreement: we could extend our SQL dialect to provide CockroachDB-specific syntax extensions that enable parallel processing. This was found agreeable because the one-shot upfront cost of updating client code to add the necessary annotations was acceptable compared to ongoing business costs caused by higher-latency transactions.
The detailed design can be found in our repository. To exploit this new feature, a client app can use the special clause RETURNING NOTHING to INSERT/DELETE/UPSERT/UPDATE. When two or more data-modifying statements are issued with RETURNING NOTHING, the local execution engine will start them concurrently and they can progress in parallel. Only when the transaction is committed does the engine wait until completion of every in-flight data update.
Distributed query processing in CockroachDB
Next to the local engine, CockroachDB also provides a distributed execution engine. What this does is to delegate parts of the processing required for a single SQL statement to multiple nodes in the cluster, so that the processing can occur in parallel on multiple nodes and hopefully finish faster. We can also expect this to consume less network traffic, for example when filters can be applied at the source.
Why, and how?
This blog post details the why and outlines the how. We will dedicate a couple separate articles to further explain how it works.
Dispelling the false idols
The usual motivation for a distributed processing engine is the observation that the data for a query is often spread over multiple nodes in the cluster. Instead of bringing the data onto a single processing node, intuition suggests we could ship the computation where the data is stored instead, and save processing time (= make queries faster).
However, at a high level, this motivation is weak: if it were for only this motivation, there is a large range of possible solutions that we would have explored besides query distribution.
For example, one could argue that there are already good non-distributed solutions to improve performance.
A strong piece of wisdom crystallized over the past 30 years can be summarized thus: data workloads in production code have been historically observed to consist of either small bursty transactions that need up-to-date and consistent views of the data, but only touch very few rows (OLTP workloads), or long wide-spanning read-only transactions that touch a lot of rows, but don't usually need a very up-to-date and consistent view of the data (analytical workloads, online or not).
From this observation, one can argue that OLTP workloads only need to talk to very few nodes in a distributed storage system (because primary and secondary indexes will narrow down the work to a few rows in storage), and analytical workloads can be run on materialized views that are maintained asynchronously in a separate system, optimized for fast throughput at the expense of consistency (as they do not need to update anything). In either case, distributed processing is not an obvious value-add.
Another conventional motivation for distributed processing is a challenge to the aforementioned wisdom, acknowledging the rise of new workloads in internet services: it is now common to find OLTP workloads that need to read many rows before they update a few, and analytical workloads that benefit from reading from very up-to-date data. In both cases, distributed processing would seem to provide an effective technical solution to make these workloads faster.
However, again this motivation is weak at a high level, because since these workloads have become commonplace, we have already seen seemingly simpler and effective technology and standards emerge to address precisely these use cases.
For transactional workloads containing large reads before an update decision is taken, the common approach is to use suitable caching. Memcached and related technology are an instance of this. For analytical processing in want of up-to-date data, an extra replication stack that maintains consistent materialized views ensures that the analytics input is both up-to-date and fast to access. Good caches and transaction/event logging to maintain materialized views externally are well-known and effective technical means to achieve this, and the corresponding technology relatively easier to provide by vendors than general-purpose distributed processing engines.
This back and forth between the expression of new computing needs and the design of specialized solutions that accelerate them is the staple diet of computer and software architects and, let's face it, the most recurring plot device in the history of computing. After all, it "just works,", right?
It works, but it is so complicated!
"Complicated", here, being an euphemism for expensive to use.
Our motivation for distributed query processing in CockroachDB
This is the point in the story where we reveal the second most recurring plot device in the history of computing: rejection of complexity. This is how it goes:
"As a programmer, I really do not want to learn about all these specialized things. I just want to get my app out!"
"As a company owner, I do not want to have to deal with ten different technology providers to reach my performance numbers. Where's my swiss army knife?"
Without a general-purpose distributed computing engine, a developer or CTO working with data must memorize a gigantic decision tree: what kind of workload is my app throwing at the database? What secondary indices do I need to make my queries fast? Which 3rd party technology do I need to cache? Which stack to use to keep track of update events in my data warehouse? Which client libraries do I use to keep a consistent view of the data, to avoid costly long-latency queries on the server?
The cognitive overhead required to design a working internet-scale application or service has become uncomfortably staggering, and the corresponding operational costs (software + human resources) correspondingly unacceptable.
This is where we would like to aim distributed processing in CockroachDB: a multi-tool to perform arbitrary computations close to your data. Our goal in the longer term is to remove the burden of having to think about atomicity, consistency, isolation and durability of your arbitrarily complex operations, nor about the integration between tools from separate vendors.
In short, we aim to enable correctness, operational simplicity and higher developer productivity at scalable performance, above all, and competitive performance in common cases as a supplemental benefit.
This is a natural extension for building CockroachDB in the first place. After all, CockroachDB rides the distributed sql wave, fuelled by the renewed interest in SQL after a period of NoSQL craze: the software community has tried, and failed, to manage transactions and schemas client-side, and has come to acknowledge that delegating this responsibility to a database engine has both direct and indirect benefits in terms of correctness, simplicity and productivity.
Our distributed processing engine extends this principle, by proposing to take over some of your more complex computing needs.
This includes, to start, supporting the execution SQL queries, when maintaining a good combination of secondary indices and materialized views is either impractical or too detrimental to update performance.
It also includes supporting some analytical workloads that regularly perform large aggregations where the results need up-to-date input data.
Eventually, however, we wish to also cater to a larger class of workloads. We are very respectful of the vision that has produced Apache Samza, for example, and we encourage you to watch this presentation "Turning the Database Inside Out" by Martin Kleppmann to get an idea of the general direction where we're aimed.
"Batteries included!"
So we are set on implementing a distributed processing engine in CockroachDB.
It is inspired by Sawzall and at a high-level works as follows:
The request coming from the client app is translated to a distributed processing plan, akin to the blueprint of a dataflow processing network.
The node that received the query then deploys this query plan onto one or more other nodes in the cluster. This deployment consists of creating "virtual processors" (like little compute engines) on every node remotely, as well as the data flows (like little dedicated network connections) between them.
The distributed network of processors is launched to start the computation.
Concurrently, the node handling the query collects results from the distributed network and forwards them to the client. The processing is considered complete when all the processors stop.
We highlight again that this is a general-purpose approach: dataflow processing networks are a powerful model from theoretical computer science known to handle pretty much any type of computation. Eventually, we will want our users to become able to leverage this general-purpose tool in arbitrary ways! However, in an initial phase we will restrict its exploitation to a few common SQL patterns, so that we can focus on robustness and stability.
In CockroachDB 1.0, for example, the distributed engine is leveraged automatically to handle SQL sorting, filtering, simple aggregations and some joins. In CockroachDB v1.1, it will take over more SQL aggregations and joins automatically. We will evaluate the reaction of our community to this first approach to decide where to extend the functionality further.

Plans for the future in CockroachDB
Lots remain to be done
Truth be told, there are some complex theoretical questions we need to learn to answer before we can recommend distributed processing as a general tool. Some example questions we are working on:
While data extraction processors can be intuitively launched on the nodes where the data lives, other processors like those that sort or aggregate data can be placed anywhere. How many of these should be launched? On which cluster nodes?
How to ensure that computations stay close to the data while CockroachDB rebalances data automatically across nodes? Should virtual processors migrate together with the data ranges they are working on?
What should users expect when a node fails while a distributed query is ongoing? Should the processing resume elsewhere and try to recover? Is partial data loss acceptable in some queries?
How does distributed processing impact the performance of the cluster? When a node is running virtual processors on behalf of another node, how much throughput can it still provide to its own clients?
How to ensure that a large query does not exhaust network or memory resources on many nodes? What to do if a client closes its connection during a distributed computation?
We promise to share our progress on these aspects with you in subsequent blog posts.
Summary: SQL processing in CockroachDB
You now know that CockroachDB supports two modes of execution for SQL queries: local and distributed.
In the local execution engine, data is pulled from where it is towards the one node that does the processing. This engine contains an optimization to accelerate multiple data updates, given some annotations in the SQL statements (RETURNING NOTHING), by parallelizing the updates locally, using multiple cores.
In the distributed execution engine, the processing is shipped to run close to where the data is stored, usually on multiple nodes simultaneously. Under the hood, we are building a general-purpose distributed computing engine using dataflow networks as the fundamental abstraction. We plan to expose this functionality later to all our users to cater to various distributed processing workloads, but for the time being we just use it to accelerate some SQL queries that use filtering, joins, sorts and aggregations, in particular those that you may not be able to, or do not want to, optimize manually using classical techniques (e.g. indexes or asynchronous materialized views).
Both engines can be active simultaneously. However, because we are working hard on distributed execution, we want users to experiment with it: we thus decided to make distributed execution the default, for those queries that can be distributed. You can override this default with SET, or you can use EXPLAIN(DISTSQL) to check whether a given query can be distributed. Subsequent blog posts will detail further how exactly this is achieved.
And there is so, so, so much more we want to share about this technology. We'll write more. Stay tuned.
But before we go... Does building distributed SQL engines put a spring in your step, then good news — we're hiring! Check out our open positions here.


