Two major cloud outages in two weeks made one thing painfully clear: your fraud defenses can’t depend on any single region or provider being perfect all the time. Microsoft’s Azure Front Door misconfiguration rippled through widely used services and status systems, just days after a separate AWS incident disrupted thousands of apps globally. These weren’t niche blips—they were broad shocks to the digital economy.
The business cost of “wait and see”
Fraud is already a trillion-dollar problem. By the end of 2025, global losses tied to cybercrime and financial fraud are estimated in the $1.2–$1.5T range. Downtime and latency make that worse: if your system can’t make a call in milliseconds, the transaction often goes through by default. Every extra second invites loss, chargebacks, and angry customers who were falsely flagged while trying to pay.
Bottom line: latency and downtime compound fraud risk and customer churn.
What leaders actually need (and what they don’t)
You don’t need yet another point tool bolted onto a fragile stack. You need a resilient decisioning fabric that:
Stays online during provider or region incidents (no single point of failure).
Decides in real time, at millisecond latency, even as volumes spike.
Scales globally with consistency, so the rules and ML decisions remain reliable across regions.
Keep false positives low, because good customers will leave if you keep saying “no.”
That fabric is what the original technical post outlined using CockroachDB plus AWS AI—only here we’ll talk outcomes, not internals.
Architecture that turns resilience into an advantage
CockroachDB as the backbone. It’s a distributed SQL database designed for scale and fault tolerance. It places data across nodes and regions, eliminates centralized bottlenecks, and now adds high-performance vector indexing so your fraud signals (embeddings) can be searched fast without brute-force scans. For you, that means always-on transaction storage and low-latency similarity search, even at massive scale.
AWS AI for intelligence. Amazon SageMaker scores anomalies (e.g., Random Cut Forest) and predicts fraud (e.g., XGBoost). Amazon Bedrock (or your embedding model of choice) turns transactions into vectors that capture behavior patterns. Those vectors land in CockroachDB, where vector indexes power fast “is this like known fraud?” lookups. Speed and brains, without the fragility.
Event-driven in real time. Kinesis streams and Lambda functions move the data, apply rules, enrich events, and write both transactional and vector data to the database in milliseconds. If a model or region stumbles, the system routes around it.
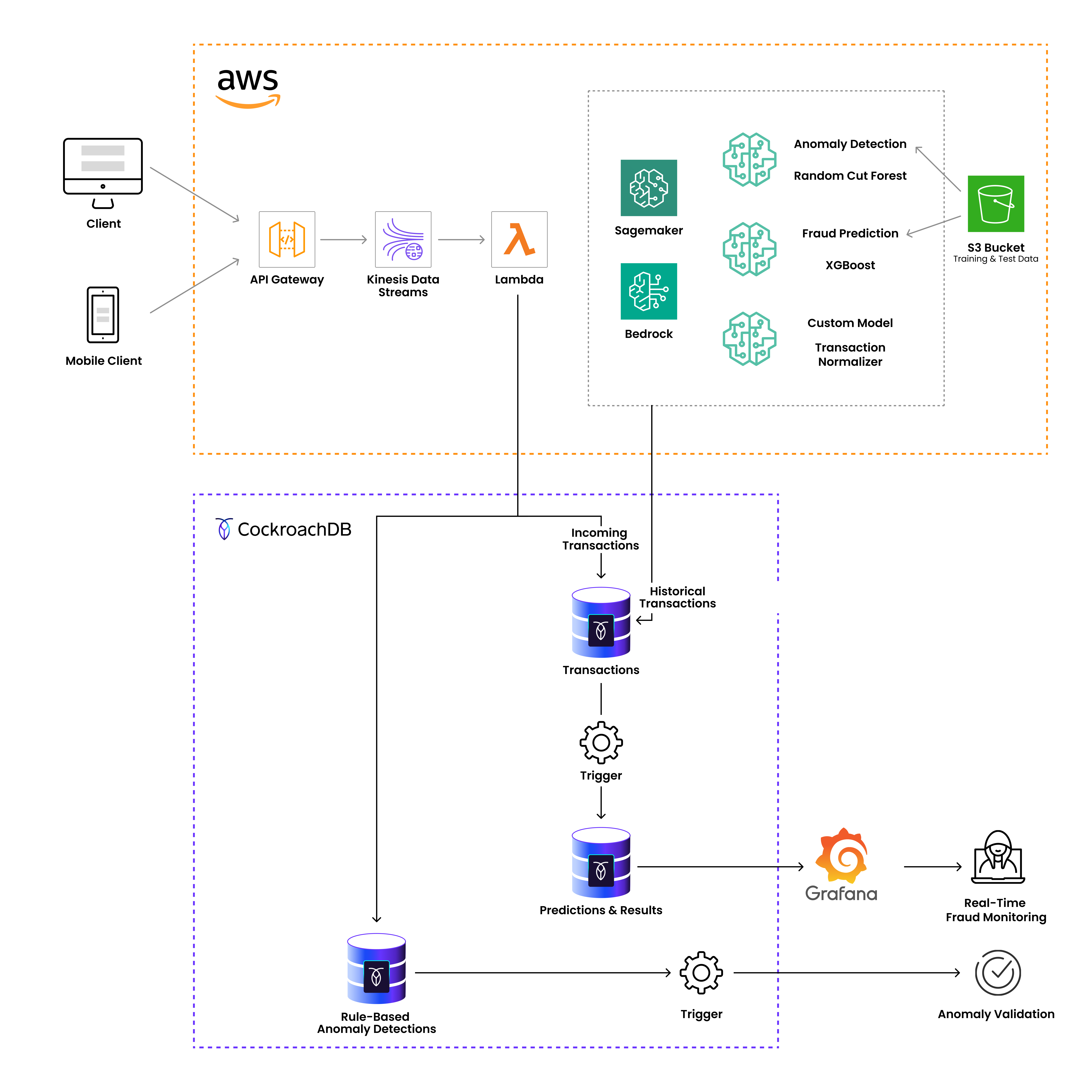
Fig: Architecture diagram showing real-time ingestion → rules → vector search → ML decision.
Why this holds up when clouds can’t
Traditional, centralized data architectures become single points of failure under stress. Distributed SQL spreads data and compute, so reads/writes keep flowing when a node or even a region is unhealthy. In CockroachDB, the new vector indexes are built to avoid coordinators and hot spots, persist state (so they don’t “forget” during restarts), and rebalance as nodes join or leave. That’s resilience translated into consistent business operations—including during high-visibility outages. C-SPANN, short for CockroachDB SPANN, is a vector indexing algorithm that incorporates ideas from Microsoft’s SPANN and SPFresh papers, as well as Google’s ScaNN project. C-SPANN organizes vectors with a hierarchical k-means structure. It first clusters similar vectors into small partitions, each summarized by a centroid—the average that best represents that group. Those centroids are then clustered again, layer by layer, creating a shallow tree. At query time, the search follows the most relevant centroids down the tree, quickly zeroing in on a tiny subset of candidates instead of scanning everything. For more technical details, read the detailed blog here.
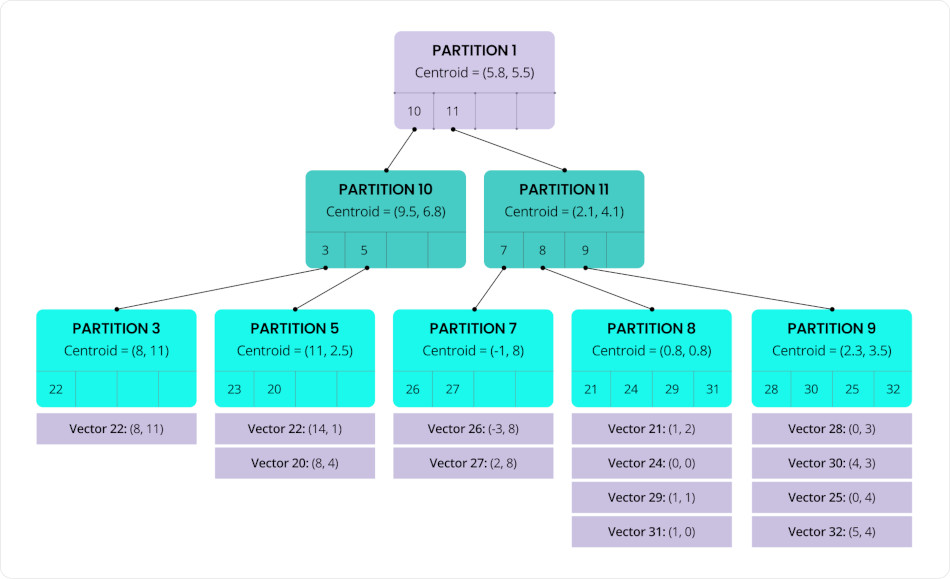
Fig: “Indexing that narrows search fast and spreads load across the cluster.”
Business outcomes (in numbers your CFO cares about)
When this architecture is in place, executives should expect movement on metrics that matter:
1) Maximizing benefits (resilience → revenue & growth)
Faster decisions: milliseconds, not seconds. CockroachDB’s vector indexes cut table scans dramatically, keeping the decision loop tight and conversion high.
Uptime during incidents: geo-distributed data + no coordinator hot spots = fewer brownouts when a region or service degrades (as the recent Azure/AWS events underline).
2) Reducing losses (protect margin & prevent churn)
Fraud loss reduction: real-time vector search + predictive models catch more bad transactions before they settle.
Lower false positives: a layered approach—rules, anomaly detection, and model-based scoring—means fewer legitimate customers get blocked (less churn, fewer manual reviews).
3) Mitigating risks (regulatory, data, and operational)
Regulatory flexibility: data can be pinned to regions to satisfy localization laws without forking your architecture or adding latency.
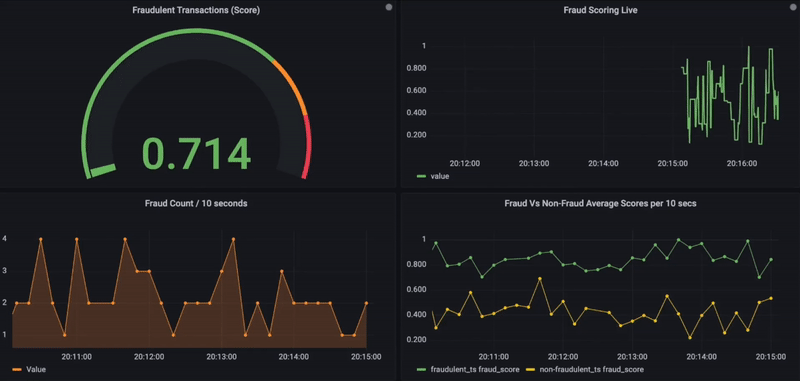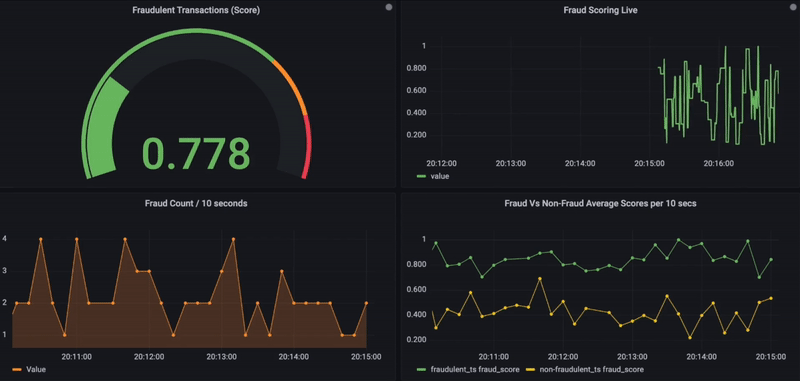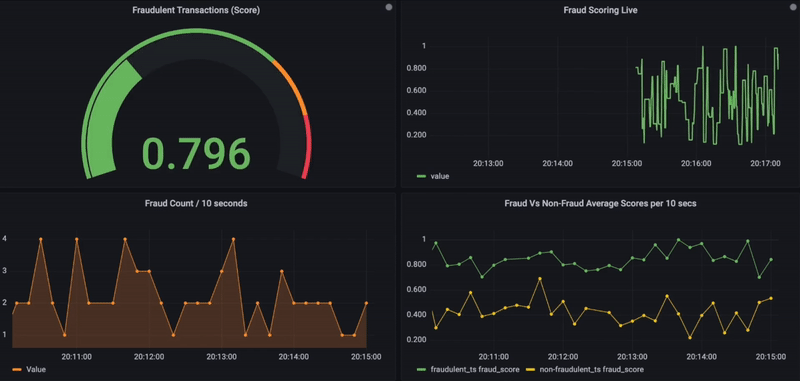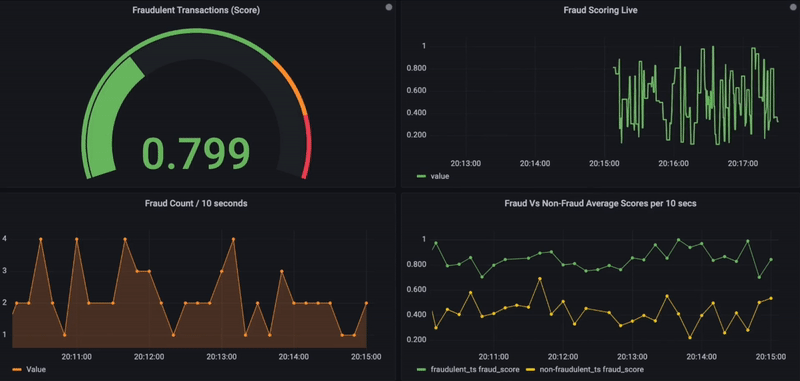
Fig. Real-Time Fraud Monitoring using Grafana.
How it breaks the “tighten vs. annoy” trade-off
Most fraud programs struggle with a trade-off: tighten controls and you annoy good customers; loosen them and the bad ones rush in. This design breaks that trap:
Pre-filters minimize waste. Cheap rules (rate-limiting, IP geofencing, device heuristics) stop obvious attempts early.
Anomaly detection finds the “weird”. Unsupervised models surface odd behavior that rules can’t keep up with.
Predictive models finalize the call. Supervised models weigh the full context for a precise yes/no with risk scores.
Vector similarity adds memory. Every decision learns from history by comparing to known fraud at low latency. No full scans; indexed, targeted search.
Result: fewer false declines, faster approvals, and lower losses—without slowing checkout.
Resilience playbook (use this to avoid the next outage)
Design for multi-AZ / multi-region from day one. Don’t wait; simulate failovers quarterly.
Pin critical data by geography. Use geo-partitioning to keep regulators happy and latency low.
Treat vector search as first-class. If embeddings drive fraud calls, the index must survive restarts and rebalance under load (not just work in a lab).
Decouple the pipeline. Streams + serverless functions isolate failures and keep ingestion/decisioning moving.
Measure what matters. Track: decision latency (p50/p95), false-positive rate, chargeback rate, uptime SLO, and model skew.
What this means for the business
This isn’t just “better tech.” It’s risk turned into advantage:
Your fraud defenses keep working when parts of the cloud don’t.
Your approvals are faster and more accurate, so more good customers sail through.
Your team stops firefighting and starts operating to SLOs with a platform that scales.
Cloud failures aren’t going away. They’re a reminder to build systems that expect failure and outlast it. The architecture above does exactly that.