

In the early years of computing, “consistency” had a clear home: the database. If your transactions were atomic and your indexes balanced, you could sleep at night knowing your system was sound.
But the world changed. Data escaped the monolith, spreading into microservices, caches, event buses, analytics pipelines, and authorization systems. Today, an end-user action can ripple through half a dozen systems: an API gateway, an identity provider, an authorization service, and multiple replicated databases, all in different regions.
Somewhere in that chain, each system needs to agree not only on what happened, but also who is allowed to know about it. That’s the new shape of consistency: not just data correctness, but permission correctness. It’s about ensuring that information and permissions evolve together in a distributed world.
At Cockroach Labs, we’ve spent years helping teams achieve data consistency at global scale. But increasingly, we see the same distributed-systems principles being applied to permissions and authorization, and the overlap isn’t accidental.
This article explains how modern authorization challenges mirror those of distributed databases, and why solving them requires the same approach to consistency. You’ll learn how CockroachDB and AuthZed work together to synchronize data and permissions globally, ensuring reliable, secure access control across distributed systems.
Why is authorization a distributed systems problem?
What is authorization? Authorization answers the question, “What can a user do once they’ve successfully logged in?” Logging into a system doesn’t mean unrestricted access. Instead, authorization ensures that users can only access what’s necessary for their role. Authorization models vary in how they determine what a user can do.
The shift from application-level access control to distributed authorization mirrors the database evolution from single-node storage to distributed SQL.
Traditional role-based access systems (RBAC) were once baked directly into the application layer. You’d check a user’s role against a local table and move on. That model collapses under global scale, where:
Users exist across multiple data regions.
Permissions depend on dynamic relationships between entities.
Permission evaluation requires context from several data sources.
Fortunately, we now have alternatives that solve authorization at scale. Modern authorization systems, such as those inspired by Google’s Zanzibar paper and implemented by projects like AuthZed, distribute authorization decisions across clusters of machines.
AuthZed focuses exclusively on authorization and provides both managed/cloud and open-source solutions via SpiceDB. This allows companies to implement secure, consistent, and scalable permissions management in modern cloud applications without building their own systems from scratch.
At its core, SpiceDB is behind the authorization model provided by all of AuthZed's products. It is designed to be entirely agnostic to authentication solutions/identity providers. SpiceDB implements a relationship-based permissions model that supports strong consistency, global replication, and extremely high scale, processing millions of authorization requests per second for modern, distributed apps.
SpiceDB is a graph engine that centrally stores authorization data (relationships, and permissions). Authorization requests (e.g., checkPermission, lookupResources) are resolved via a dispatcher that traverses the permission graph.
But this design introduces the same fundamental challenges that distributed databases face:
How do you guarantee that every permission check reflects a consistent view of the state?
How do you manage replication lag and cache invalidation?
How do you reason about correctness in the presence of concurrent updates?
Authorization, in other words, is a distributed systems problem. It’s no longer just about security, it’s about coordination.
How does CockroachDB enable consistent permissions?
When data architects discuss “consistency,” they’re usually referring to the “C” in ACID, ensuring that every transaction moves the database from one valid state to another.
But in distributed systems, that concept fragments. There are now multiple planes of consistency:
Data Consistency: The database’s view of the world.
Permissions Consistency: The authorization system’s understanding of who can access what.
Operational Consistency: The coherence of event streams, caches, and background jobs that rely on that data.
These planes must evolve together. If your data updates before your authorization system sees the change, you risk stale permissions. If your permission revokes access before data is updated, users might experience transient denials or errors.
The goal isn’t perfect simultaneity, that’s physically impossible in distributed systems, but predictable coherence: every component observing a consistent timeline of events.Just as databases evolved to handle distributed consistency, authorization systems are undergoing a similar transformation, and that’s where CockroachDB’s guarantees matter.
CockroachDB was built around this principle: Its serializable isolation model provides the strongest transactional consistency guarantee in SQL, not “eventual,” not “read-committed,” but linearizable across a global cluster. That same property is what emerging authorization systems are now chasing, but for policy instead of data. That’s why SpiceDB uses CockroachDB as the underlying datastore. With this design, it gains a globally distributed, strongly consistent SQL foundation.
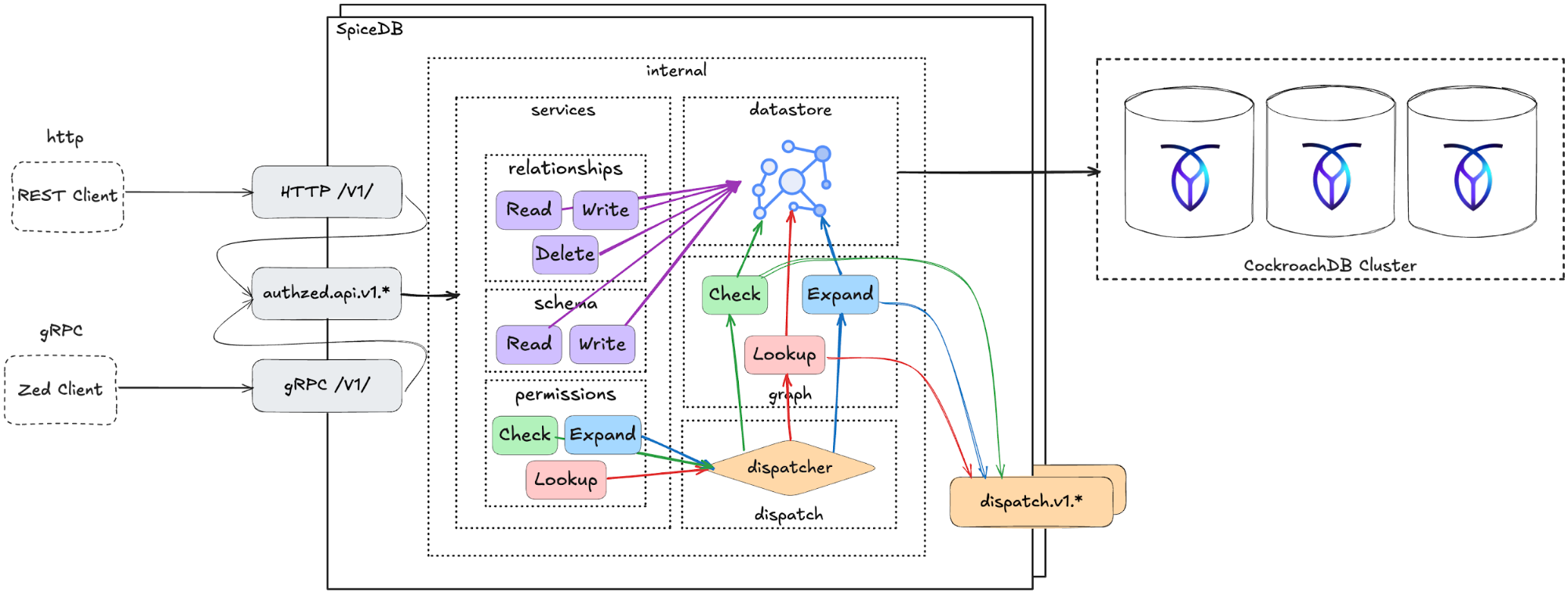
SpiceDB internals wired to CockroachDB cluster
CockroachDB’s multi-region replication and high availability ensure that authorization decisions are consistent, low-latency, and resilient across geographies. Taken together, this architecture combines SpiceDB’s flexible, API-first authorization model with CockroachDB’s fault-tolerant database platform to deliver secure, fine-grained and strongly consistent access control that scales to enterprise workloads worldwide.
The Parallels Between Databases and Authorization Systems
Architects often design distributed databases and authorization systems separately. But when you line up their challenges, the resemblance is striking.
Both domains require:
Ordering guarantees (what happened first)
Idempotency (safe retries)
Consistency under concurrency (no conflicting states)
Observability (knowing what the system believes at any moment)
This conceptual overlap creates a design opportunity: If your database already guarantees global consistency and provides a reliable change history, it can act as the “anchor of truth” for higher-level systems like authorization and access control systems.
Practical Example: How to use CockroachDB and AuthZed together?
Let’s unpack this in practice. We’ll show how CockroachDB can serve as the source of truth for data and policy consistency by modeling a global project management app with authorization checks powered by AuthZed.
Imagine we’re building a global content management application that uses SpiceDB, as the access control system backed by CockroachDB across multiple regions.
0. Prerequisites
To execute this scenario with success, you’ll need:
a secure, reachable CockroachDB cluster (self-hosted or Cloud), a current supported CRDB version, and network access from your SpiceDB runtime to port
26257.Create a dedicated database
spicedband user for SpiceDB, granting enough privileges to run its migrations and operate normally.
On the SpiceDB side, you need to install the binary/container or use the Kubernetes Operator, then run the following command:
spicedb datastore migrate head --datastore-engine=cockroachdb --datastore-conn-uri="postgres://root@CRDB_URI:26257/spicedb?sslmode=disable"then, start the SpiceDB service pointing at your CockroachDB URI:
spicedb serve --grpc-preshared-key="<preshared_key>" --http-enabled=true --datastore-engine=cockroachdb --datastore-conn-uri="postgres://root@CRDB_URI:26257/spicedb?sslmode=disable"To interact with SpiceDB through the zed (AuthZed) CLI, you need to install the latest binary releases of zed using the official tap:
brew install authzed/tap/zed
Once installed you can connect to the SpiceDB exposed in the client with the command below. For local development we can use the --insecure flag to connect over plaintext. Be sure to use the same preshared_key you used in the spicedb serve command.
zed context set my_context <SpiceDB_IP>:50051 <preshared_key> --insecureYou can check the above command worked by running:
zed version
If the output of zed version shows the server version as “unknown” then your CLI was unable to connect, so you may need to double check some values in the previous steps such as the preshared_key, the IP or the port your SpiceDB instance is running on.
1. Defining the schema
Writing one or more object type definitions is the first step in developing an authorization relationship schema.
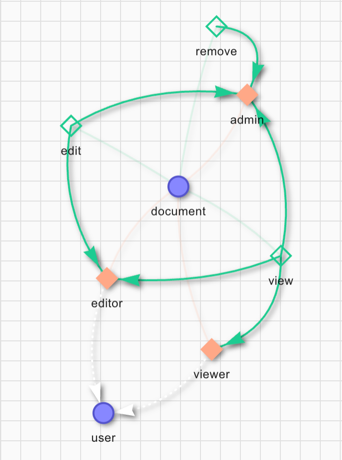
Authorization relationship schema
In the example above, we define the user and document concepts. The user can be a viewer, an editor or admin. The definition gives the remove permission to the admin role only. To edit a file the user must be either an editor or admin. The permission to view a document is set for viewer, editor and admin roles. The syntax of the schema definition is the following:
definition user {}
definition document {
relation editor: user
relation viewer: user
relation admin: user
permission view = viewer + editor + admin
permission edit = editor + admin
permission remove = admin
}
Once the schema, which defines the resources and necessary permissions, has been created, it can be saved in SpiceDB using either the zed CLI or its APIs (REST and gRPC). Although the REST API is less performant and not tested at scale, making gRPC the preferred choice, we will utilize the REST API for demonstration purposes to highlight its features.
First, let’s save the schema created earlier as schema.zed and execute the following command:
zed schema write ./schema.zed
If it works, we should see our authorization schema printed when the following command is executed:
zed schema read
There exists another less recommended way to store the schema in SpiceDB, using the REST API. In this case, the schema definition is embedded into the request body:
curl --location 'http://<SpiceDB_IP>:8443/v1/schema/write' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <preshared_key>' \
--data '{
"schema": "definition user {} \n definition document { \n relation editor: user \n relation viewer: user \n relation admin: user \n permission view = viewer + editor + admin \n permission edit = editor + admin \n permission remove = admin \n}"
}'
# output:
# {"writtenAt":{"token":"GhUKEzE3NTgxMjkyOTM0MDE2MDYxNDA="}}
2. Creating relationships
In SpiceDB relationships are represented as relation tuples. Each tuple contains a resource, a relation and a subject. In our case the resource is the name of a document, the relation is either admin, viewer or editor, and the subject is the name of a user.
Let’s simulate a new content creation flow: a user amine creates a new document called (doc1) and becomes its admin, meaning he can do everything to doc1 (view, edit, and remove). Let’s assume an additional user jake with the viewer role for document (doc1).
zed relationship touch document:doc1 admin user:amine
zed relationship touch document:doc1 viewer user:jake
Now jake can only view the document doc1. We can seed another test user evan and add him as editor of document doc1 using the REST API.
curl --location 'http://<SpiceDB_IP>:8443/v1/relationships/write' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <preshared_key>' \
--data '{
"updates": [
{
"operation": "OPERATION_TOUCH",
"relationship": {
"resource": {
"objectType": "document",
"objectId": "doc1"
},
"relation": "editor",
"subject": {
"object": {
"objectType": "user",
"objectId": "evan"
}
}
}
}
]
}'
# output :
# {"writtenAt":{"token":"GhUKEzE3NTgxMjk3MDg2NTc4MDQ5ODk="}}
3. Checking permissions
To check that our schema is working correctly we can issue a couple of check requests. As jake is only a viewer for doc1 we expect him to have the view permission but not the edit or remove permissions.
zed permission check document:doc1 view user:jake
# output: true
zed permission check document:doc1 edit user:jake
# output: false
Now, let’s check that jake doesn’t have the remove permission on document doc1, this time using the REST API:
curl --location 'http://<client IP>:8443/v1/permissions/check' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <preshared_key>' \
--data '{
"consistency": {
"minimizeLatency": true
},
"resource": {
"objectType": "document",
"objectId": "doc1"
},
"permission": "remove",
"subject": {
"object": {
"objectType": "user",
"objectId": "jake"
}
}
}'
# output :
# {"checkedAt":{"token":"GhUKEzE3NTgxMjk5NTAwMDAwMDAwMDA="}, "permissionship":"PERMISSIONSHIP_NO_PERMISSION"}
Conversely, as amine is an admin, we expect him to have all permissions.
zed permission check document:doc1 view user:amine
# output: true
zed permission check document:doc1 remove user:amine
# output: true
zed permission check document:doc1 edit user:amine
# output: true
From schema to global consistency
Once your authorization schema is defined and applied, every relationship and permission change becomes a transaction backed by CockroachDB’s serializable isolation model. This ensures that your application’s understanding of “who can do what” never drifts out of sync, regardless of geography or scale. Whether a user is in New York, Sydney, or Frankfurt, the same check will always return the same result, anchored to the same consistent state.
For example, when a viewer is promoted to an editor, that change is immediately reflected across all regions, atomically and without replication lag. When access is revoked, no cache or replica continues to serve stale permissions (except when using minimize_latency, permission can be up to five seconds stale). This tight coupling between authorization data and CockroachDB’s transactional guarantees eliminates the race conditions and timing gaps that often arise in distributed systems, ensuring that your permissions are always as current as your data.
Consistency doesn’t stop at correctness, it extends to visibility. In complex distributed environments, understanding why a particular authorization decision was made is just as critical as making it correctly. To avoid the dual write problem, and all the challenges that come with it, CockroachDB’s changefeeds can stream every policy mutation (i.e., permission grants, revocations, and role updates) into event systems like Kafka or Pub/Sub.
When paired with AuthZed’s audit logs, this creates a comprehensive observability layer for your authorization graph. Developers and compliance teams can monitor authorization data changes in real time, replay historical events for audits, and reconcile expected versus actual authorization states automatically. With this architecture, authorization becomes a measurable, testable component of your infrastructure, no longer a black box buried in application code.
Where do CockroachDB and AuthZed win together?
Understanding how AuthZed structures its offerings helps clarify where CockroachDB fits in the broader authorization landscape. AuthZed focuses exclusively on authorization infrastructure (not authentication or identity management) and delivers its solutions through SpiceDB, a high-performance, relationship-based permission database inspired by Google’s Zanzibar.
SpiceDB is the core engine behind all AuthZed products, available in multiple forms depending on deployment and support needs:
SpiceDB (Open Source): The foundational, community-driven version of the authorization engine, free to use and self-hosted under the Apache 2.0 license.
SpiceDB Enterprise: A self-managed enterprise edition that includes audit logging, fine-grained API control, FIPS-validated cryptography, and dedicated support.
AuthZed Dedicated: A fully managed, single-tenant SaaS offering that provides all enterprise features along with global, regionally distributed deployments and integrated APIs for permission filtering.
AuthZed Cloud: A multi-tenant managed platform designed for teams that want to start quickly without operational overhead.
Across all these tiers, CockroachDB plays a critical role as the underlying datastore. In a world where authorization, uptime and resiliency are non-negotiable, a single missed permission update can translate into security or access errors.
CockroachDB’s multi-active architecture allows these deployments to survive node, availability zone, or even regional outages with zero downtime. More importantly, it enables horizontal write scalability, letting AuthZed support real-world workloads that reach tens of thousands of writes per second.
The synergy is clear: CockroachDB provides the foundation of global consistency and resilience, while AuthZed delivers the specialized authorization layer on top. Together, they power distributed systems where both data integrity and policy correctness scale hand-in-hand.
Bringing authorization and distributed systems together
The challenges of distributed systems have always revolved around keeping data in sync across space and time. But as data architectures become more composable and interconnected, the same principles must now extend beyond the database, to the very rules that govern access, privacy, and security.
Ensuring policy correctness alongside data correctness isn’t just a security concern; it’s a consistency challenge. Systems that don’t evolve both attributes together risk inconsistent user experiences, compliance issues, and operational fragility.
Enterprises that pair CockroachDB’s globally consistent, fault-tolerant data layer with AuthZed’s distributed authorization model gain a distinct business advantage: They can design systems where policy and data evolve reliably, predictably, and at planetary scale.
Curious how CockroachDB and AuthZed can simplify your authorization model? Let’s talk about what reliable permissions look like at scale.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Amine El Kouhen, Ph.D., is Sr. Partner Solutions Architect at Cockroach Labs. Amine is a Senior ISV Partnerships leader at Cockroach Labs (CRL), working on technical certification, innovation, GTM, and co-sell initiatives with CRL's strategic GSI and ISV partners. With more than 20 years of experience in implementing and supporting SQL, NoSQL and NewSQL databases, he held leadership and hands-on roles that span new market entry, GTM planning, and partner development. Amine holds a Ph.D. in Computer Sciences and was a former research associate in data and software architecture at Concordia University.


