

Nearly every organization has critical systems that need to be up at least 99.99% of the time. Typically, these systems need to recover from downtime in seconds with no data loss while serving vital customers located across an entire country, many countries, or even continents.
In response, enterprise companies along with cloud and SaaS providers are developing “multi-region architectures” to tackle these resilience and geography challenges. Building multi-region systems is complex because they need to:
Quickly route dispersed requests to the closest cloud region gateway.
Accommodate stateless app services running simultaneously in many regions.
Ensure users have fast responses no matter where they are located on the planet.
Managing data is often the hardest part of building systems that require a multi-region architecture. There are a variety of solutions to multi-region challenges, all with various tradeoffs. In this blog post, we’ll touch on several solutions and introduce a compelling strategy based on a CockroachDB multi-region database.
How public clouds make multi-region architectures possible
Public cloud providers like AWS, Azure, and GCP consist of physically separate data centers called availability zones. Availability zones are grouped into regions based on geography.

Cloud providers distribute availability zones and regions across the planet to enable high levels of system resilience and failover tolerance.
Leveraging this very resilient global cloud infrastructure, a new class of mission-critical applications and data is emerging in which an application and its data are deployed in multiple cloud regions. They are called multi-region architectures.
Resilient multi-region architectures: High Availability and Continuity of Operations
Mission critical-applications require high availability and continuity of operations.
What is High Availability?
High availability is the amount of required system uptime within a defined period of time. For example, four nines of uptime, 99.99%, means a system can be down for no more than 52.60 minutes per year.
What is Continuity of Operations?
While cloud providers try to ensure high availability, they cannot prevent zone, region, and other infrastructure failures from occurring. That’s where the continuity of operations of our systems becomes important to measure and manage. Many companies use two important metrics.
Recovery Time Objective (RTO) : the maximum amount of time a system can be down before there is an unacceptable impact on the business or other systems.
Recovery Point Objective (RPO) : the point in time prior to the outage, to which data needs to be recoverable. In other words, how much data loss is acceptable?

For mission-critical systems, businesses target 99.99% uptime or higher and as close to zero RTO and RPO as possible. Multi-region architectures are a way to design, build and operate systems that meet these goals.
Transactional SQL relational databases in multi-region architectures
Modern systems use different data consistency models–from eventually consistent to strongly consistent–for different business use cases. Strongly consistent transactional databases are often used for mission-critical metadata and system-of-record data. It’s fundamental to the business that this data is never lost and is always consistently correct no matter what part of the system is accessing it.
There are different approaches in multi-region architectures to achieve low RTO and RPO for mission-critical data in transactional SQL databases. Many define a primary cloud region where an active writable SQL database is deployed together with one or more secondary cloud regions where data is passively replicated for disaster recovery purposes. In these multi-region architectures, if the primary region goes down, it’s common to see 10-15 minutes of maximum recovery time of the data system (RTO) and up to 5 minutes of acceptable data loss (RPO).
For many applications an RTO/RPO that high is simply not good enough. For this reason, CockroachDB takes a different approach. CockroachDB is built as a cloud-native, globally-distributed SQL database from the ground up. A single CockroachDB multi-region cluster and database can run actively in multiple cloud regions or even multiple clouds. CockroachDB actively replicates transactional writes across cloud regions, handling cloud region failures transparently to application clients.
That means achieving four nines or more of high availability with near zero seconds of recovery (RTO) and zero data loss (RPO) is possible with CockroachDB’s multi-region capabilities. That’s a unique and exceptional level of SQL database continuity of operations in multi-region architectures.
How to setup a resilient multi-region CockroachDB database
It’s straightforward and easy to set up a resilient multi-region CockroachDB database. There are only three steps.
Step 1 - Start a CockroachDB multi-region cluster
Start the nodes of the CockroachDB cluster in various cloud provider regions. We’ll do this by starting a “self-hosted” CockroachDB cluster. Using CockroachDB dedicated and CockroachDB serverless is even easier.

cockroach start \
--locality=region=us-west-1 \
--join…We start each node in our CockroachDB cluster with multi-region capabilities. We’re using the cockroach CLI tool installed on each server where we’ll start a node. Let’s define each command:
startcommand starts this node as part of a multi-node CockroachDB cluster.--localityincludes key-value pairs describing the location of the node in the cluster.--locality=regionkey is required to start a CockroachDB multi-region cluster.--locality=region=us-west-1uses theregionvalueus-west-1, mimicking the underlying cloud provider topology which is considered a best practice. CockroachDB multi-region calls this a “cluster region.”--join...describes the IP or alias locations of the nodes in the cluster.
Our second and third nodes run in the same cloud region, so we repeat the cockroach start command with the same locality us-west-1. This results in all three nodes sharing the same cluster region.
But, what if we want to also include the cloud provider availability zone locations? In some circumstances, zone level locality is useful when configuring a CockroachDB multi-region cluster. So, let’s restart these nodes using region=us-west-1 and zone=<whatever the zone name is>.
cockroach start \
--locality=region=us-west-1,zone=usw1-az1 \
--join…

CockroachDB understands that region is always the top of any tiered locality structure: zones are included or nested under the region.

We repeat this step, starting nodes in all the regions. All together we call this the CockroachDB cluster’s “multi-region architecture.” If you’re familiar with how a CockroachDB multi-node cluster works, CockroachDB spreads a database’s table range replicas across as diverse a set of region,zone localities within the cluster as possible.

Step 2 - Add database regions
Imagine creating a movr_rides database in the above with a table called rides. At this stage the movr_rides database is not a “multi-region database.” Instead, it will operate as a database in a CockroachDB multi-node cluster, not a multi-region cluster.
What does that look like? We know that the rides table has rows of data segmented into ranges. Each range group consists of a default of three range copies or replicas, with one of them being the leaseholder. CockroachDB will balance the distribution of those range replicas and leaseholders across all nine nodes in the three regions.
Notice that so far, there isn’t a way for us as developers, administrators or engineers to influence CockroachDB’s replication distribution pattern. We can however influence the distribution pattern if we use CockroachDB specific multi-region SQL. Influencing the replication distribution pattern could be very handy if we could place leaseholders near most of our application clients, speeding up their reads and writes! But in order to do that we first need to tell CockroachDB that the movr_rides database is a “multi-region database.”
We do that using a multi-region SQL statement that sets a “primary region” on the movr_rides database. Note that the primary region is ᐦus-east-1ᐦ. Secondly, we add two other “non-primary” regions to the movr_rides database.
> ALTER DATABASE movr_rides SET PRIMARY REGION ᐦus-east-1ᐦ;
> ALTER DATABASE movr_rides ADD REGION ᐦus-central-1ᐦ;
> ALTER DATABASE movr_rides ADD REGION ᐦus-west-1ᐦ;

It’s important to note that you need three or more regions in order to have a database that is resilient to underlying cloud provider region failure: with three regions, if one cloud region fails, two remain.
Step 3 - Set a region survival goal
In our final step, we influence the database’s table range replica and leaseholder distribution pattern. We do that by setting a region survival goal on the movr_rides database.
ALTER DATABASE movr_rides SURVIVE REGION FAILURE;The statement is CockroachDB specific multi-region SQL. It impacts the distribution and location of table ranges in the movr_rides “multi-region database.”

As we know, normally each table range group consists of a default of three range copies or replicas, with one of them being the leaseholder. In a CockroachDB multi-region cluster, a database with a region survival goal and three added regions–what we have done so far with the movr_rides database–gets an additional two replicas per table range group. The new multi-region distribution pattern of the rides table range groups is 2-2-1. The primary region us-east-1, gets two replicas for each range group, one being the leaseholder.

We know that application clients’ read and write requests to a CockroachDB database go through the table data range leaseholders. Thus all application clients, no matter where they are geographically located, go through the us-east-1 region leaseholders.
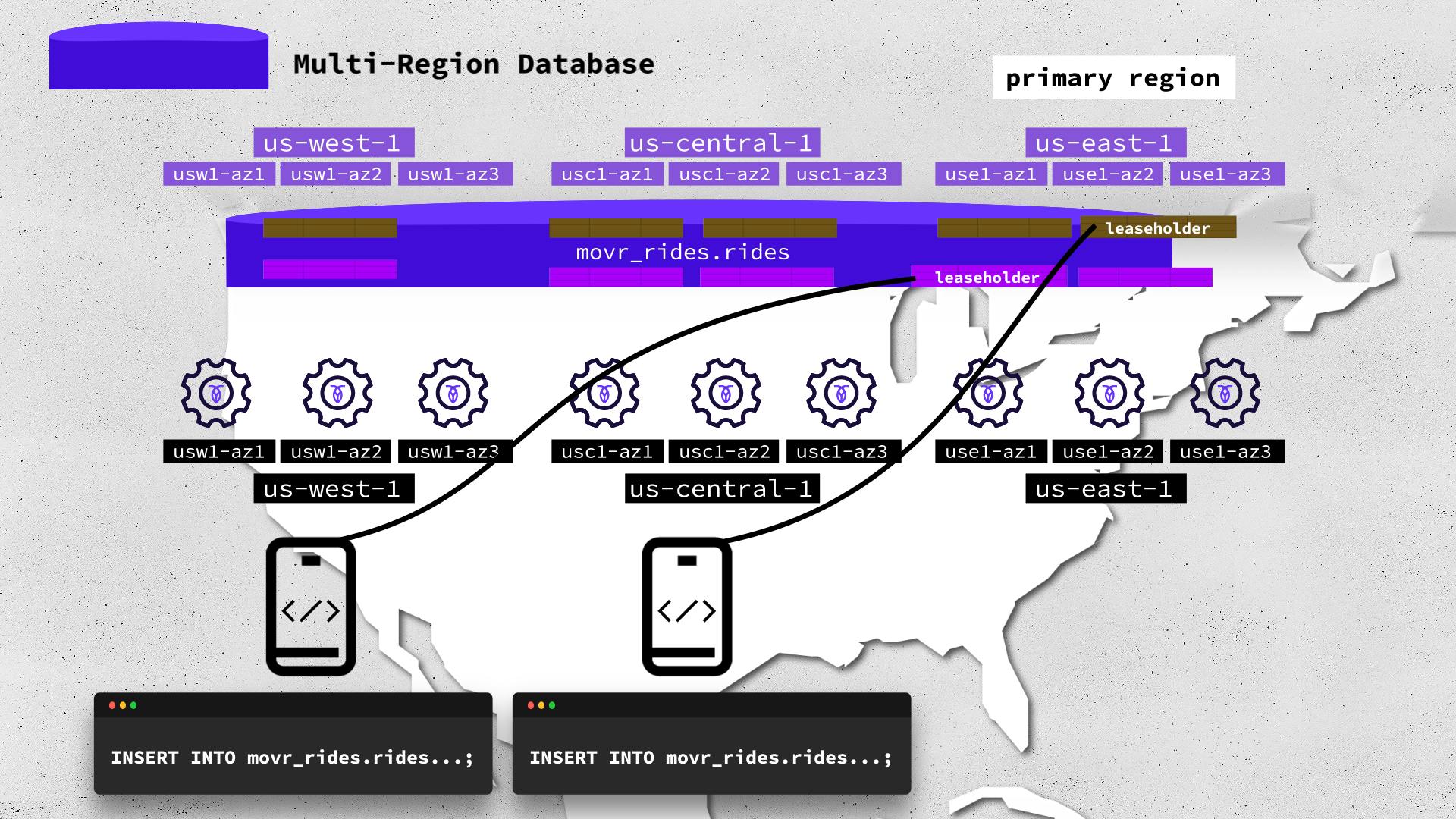
So what does this mean for the resilience of our movr_rides multi-region database in the three cloud provider regions? Any single cloud region can fail and the movr_rides database range groups will still have at least a 3 of 5 majority quorum. And even if the primary region us-east-1 fails, its leaseholders are elected in another region.

The result: the movr_rides database is still available. Application clients can continue to write and read data, there is zero data loss (RPO) and recovery time happens in seconds (RTO).
…
If you want to learn the practical skills to do this with your mission-critical data check out the new Cockroach University course: Building a Highly Resilient Multi-Region Database using CockroachDB. Take a look at this short video to learn more about what will be covered in the course:


