
A modern distributed database should do more than just split data amongst a number of servers; it should correctly manage partitions (or shards). Moreso, it should automatically detect failures, fix itself without any operator intervention, and completely abstract this management from the end user.
This post is the first in a series on how CockroachDB handles its data and discusses the mechanisms it uses to rebalance and repair. These systems make managing a CockroachDB cluster significantly easier than managing other databases.
Data Storage
Before we get into the details of automated rebalancing and repair, we’re going to have to start at the basics. So let’s take a quick look at how CockroachDB stores, partitions, and replicates data.
Data is Stored as Key Value Pairs Partitioned into Ranges
CockroachDB stores all user data and almost all system data in a giant, monolithic, sorted map of key value pairs. This keyspace is divided into what we call ranges, contiguous chunks of the keyspace, so that every key can always be found in a single range. A key may have a corresponding value, and if it does, this value is stored in that range.

This figure depicts the full keyspace with each blue line intersecting with the horizontal keyspace denoting a key that’s been inserted. Each key has some random value associated with it. Note that the keys are in alphabetic order. This keyspace is then subdivided into ranges (subsets of the keyspace), shown here as sideways parentheses. No ranges ever overlap and every key, even ones that have not yet been written to, can be found in an existing range.
Now there’s something missing here. This is clearly just the key-value layer and we’re a distributed SQL database. All SQL tables, rows, columns and index entries are mapped to keys behind the scenes. To see how this works, this post covers most of the details.
Ranges are Distributed
CockroachDB is a distributed database designed to be run across multiple nodes (servers or VMs) joined together into a single cluster. Given this design, it wouldn’t make sense for all ranges to reside on a single node, so CockroachDB spreads the ranges evenly across the nodes of the cluster:

In this figure, each range is assigned to a node. What’s important here is that that ranges can be on any node and that more than one range can be a node.
Ranges Split as They Grow
As more data is added to the system, more keys will have values associated with them and the total size of the data stored in ranges will grow. CockroachDB aims to keep ranges relatively small (64 MiB by default). This size was chosen for two reasons. If the ranges are too large, it means that moving a range from one machine to another becomes a very slow task, which would slow down the cluster’s ability to repair itself (more on this in a bit). However, if the ranges are too small, then the overhead of indexing them all starts to become a problem. So when a range becomes too large, it’s split into two or more smaller ranges, and these new ranges represent slightly smaller chunks of the overall keyspace. When a split occurs, no data move around, only range metadata does, so the new range will be on the same node as the one it split from.
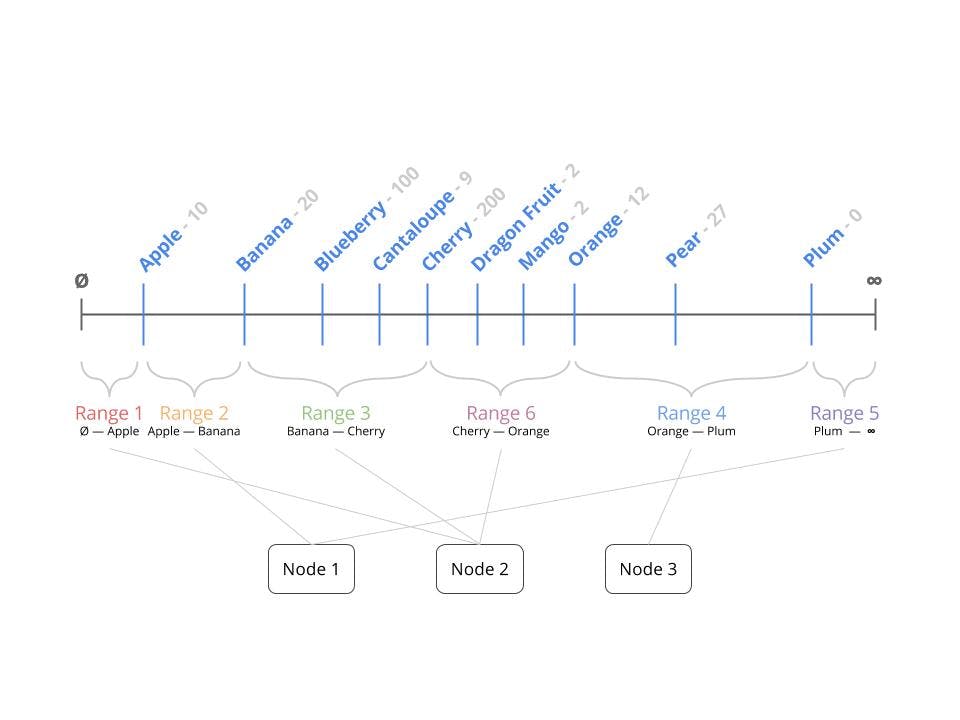
In this figure, some new keys have been inserted and they all happened to fall into Range 3. As a result, Range 3 has become too large and needs to split. It splits into a smaller Range 3 and adds a new Range 6. Note that Range 6 will at first be on the same node as Range 3, since no data has moved during the split, just that some of Range 3’s keys have been assigned to the new range.
Ranges are Replicated
Organizing the keyspace into ranges makes it possible to store and distribute data efficiently across the cluster, but that alone doesn’t make the cluster robust against failure. For fault tolerance, it’s vital to have more than one copy of each key and value. To that end, CockroachDB replicates each range into what we call replicas (3 times by default), storing each of these replicas on a different node. The more replicas a range has, the lower the chance of data loss from failures, but of course, each change will have to be copied to a larger number of replicas. It’s important here to note that a write command only requires confirmation from a majority of replicas. This means that while latency does increase with the addition of more replicas, only a subset actually affect the latency of that write. To keep all the replica in sync, CockroachDB uses the Raft consensus algorithm. For a more in depth look at Raft, give this video a watch.
It’s probably best to to clarify the terminology here. A range is actually an abstract concept, specifically owning a span of the keyspace. While a replica is a physical copy of all the keys and values within that span. So when a range splits, it happens on all replicas at the same time. The Raft consensus algorithm functions on the range’s level, keeping all of its replicas in sync.
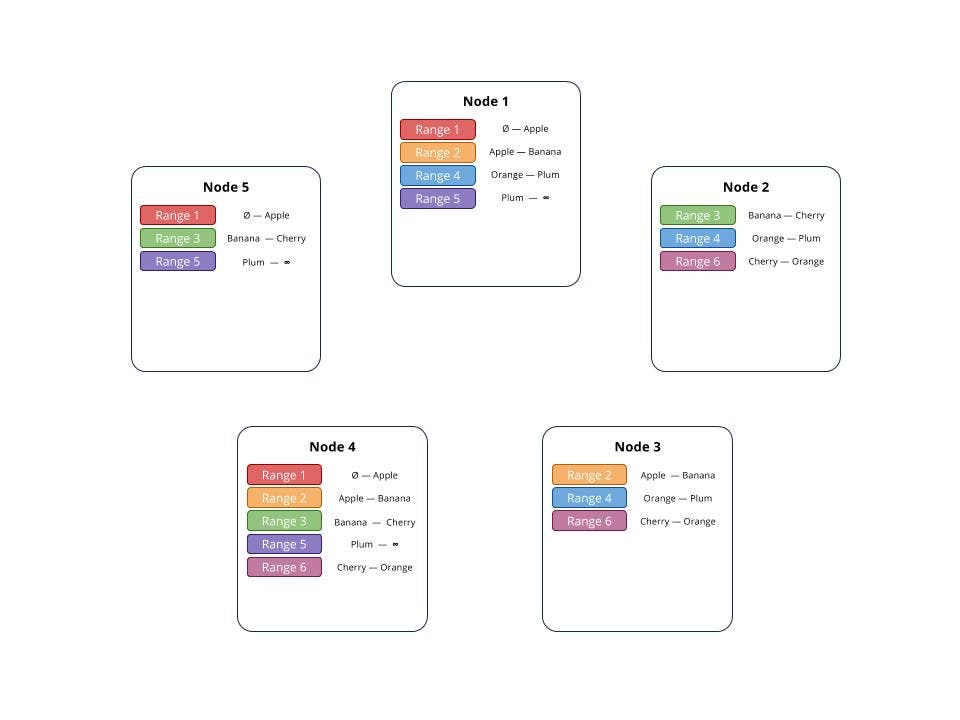
In this figure, we’re going to zoom out, and look at each node. Here 5 nodes are depicted, each with a collection of replicas. Each range from earlier is coloured the same way to make them easier to differentiate. Note that while in this diagram no two ranges have replicas on the same set of nodes, there is no system in place to prevent that.
For a range to be considered available to serve reads and writes, a quorum (anything greater than 50%) of replicas must be present. With this in mind, when a single node fails (for whatever reason), the rest of the cluster can keep functioning. This ability to continue functioning during failures is one of the key advantages of a distributed system. But being distributed isn’t enough. If there is no automated repair policy, the next failure might cause some data to become unavailable.
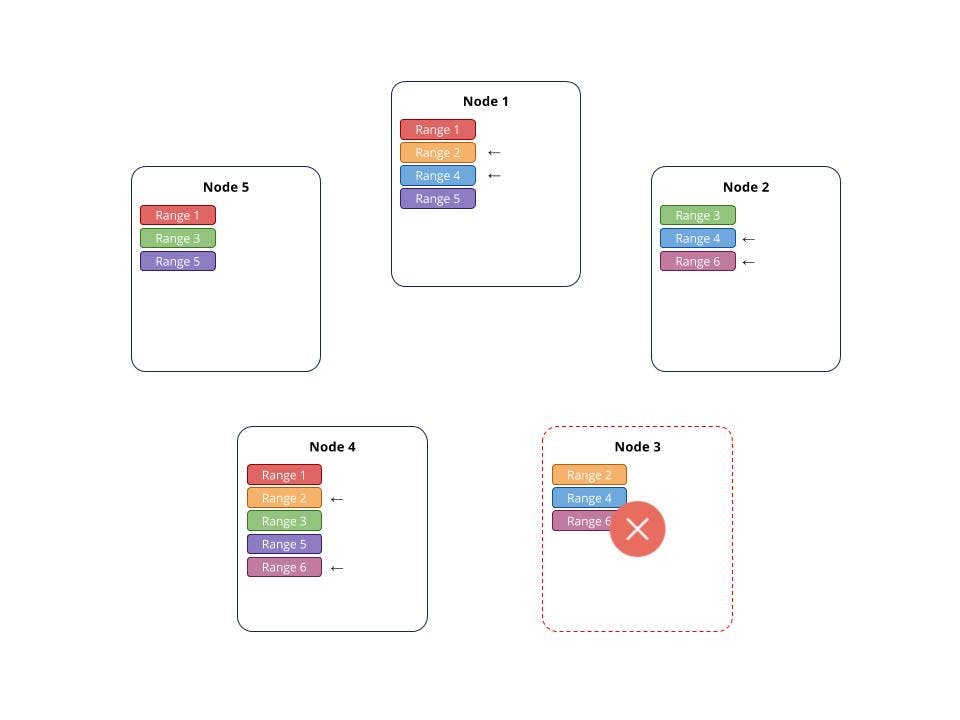
In this figure, we can see that in the case of a single node failure, Node 3, the cluster as a whole can still function, including the ranges that have replicas on the dropped node. A quorum (>50%) of replicas is required to maintain availability. All affected ranges clearly have 2 copies and are thus still available. If a 2nd node was affected, there may be some ranges that could become unavailable.
Due to their small size (as discussed earlier), replicas can be moved quickly and freely between nodes. This is a key point on how CockroachDB automatically balances the cluster, and we’re going to get back to it in a bit.
How We Know Where Range Replicas Live
To keep track of on which nodes all of these replicas reside, we keep a two-tiered index into all ranges’ replicas. We call these the meta indexes. For each replica, a key in the first-level index points to a key in the second-level index, which in turn points to the actual locations of the data.
These meta indexes must always be accurate in order for queries to find the keys they’re functioning on so they are stored just like all other data, as replicated ranges, but in a reserved portion of the keyspace. Whenever CockroachDB moves, adds, removes, or splits these ranges, it therefore does so with the same level of data integrity as for all other data in the system. This is a very significant benefit of CockroachDB, as it means applications never need to know anything about the location of data. They just query any node in the cluster, and CockroachDB handles data access behind-the-scenes.
Automated Repair
Now that we’ve mapped out how CockroachDB stores data as replicated ranges, what happens when somebody unplugs one of your servers, or a hard drive fails, or some other disaster inevitably occurs?
Let’s return to our example above. When a single node fails, all the ranges that have replicas on that node are now missing a replica.
Temporary Failure
If this failure is temporary, each range will still have a quorum of replicas (66%, assuming each range starts with 3 replicas), so incoming requests will continue to be handled seamlessly.

This figure shows that while Node 3 is still disconnected from the cluster, all replicas on that node can become stale. Range 4 had a number of new writes. Range 6 had some deletes. And Range 2 has split into Range 2 and Range 7.
When the failed node comes back online and brings the missing replicas with it, it will quickly catch up restoring the specified level of fault tolerance.

This figure demonstrates that when Node 3 reconnects, its stale replicas will catch up, including the split operation of Range 2 to Ranges 2 and 7. If there were further changes to range 7, it also will need to catch up.
There are 3 ways in which a replica will catch up with a range once reattached to the cluster: If no changes were made to the range, the replica will simply rejoin the range. If there were only a few changes to the range, the replica will receive and process a list of commands in order to catch up. If the number of changes are large the replica will receive a snapshot of the current state of the range. This is the most expensive operation in terms of time, but since the limit for the size of a range is 64 MiB, it can be done quickly. If the range is active, even once that snapshot has been processed, there may still be some new commands that need to be applied.
Permanent Failure
But what about the case in which the node does not return? In this case, the loss of any other node could potentially result in a loss of a quorum of replicas for some ranges. This loss would in turn make those ranges’ data unavailable. This is a fragile state we don’t want the cluster in for very long, so once a node has been missing for five minutes, it is considered dead, and we automatically start the repair process. This five minute time is a customizable cluster wide setting server.time_until_store_dead which can be changed proactively if there is a longer than five minute downtime expected on a node.
How We Repair
Each CockroachDB node is continuously scanning all of its ranges. If any node notices that one of its range’s replicas is on a dead node, a new replica is added on a healthy node and the dead replica is removed. Since the ranges needing repair are distributed throughout the cluster, this repair process occurs across the system and the replicas being added will also be spread out. When a node is removed, there may be lot of ranges to repair, so these repairs are done at a slow yet steady pace designed to not impact latency. This process is based on the same heuristic we use for rebalancing data, which we’ll talk about next.
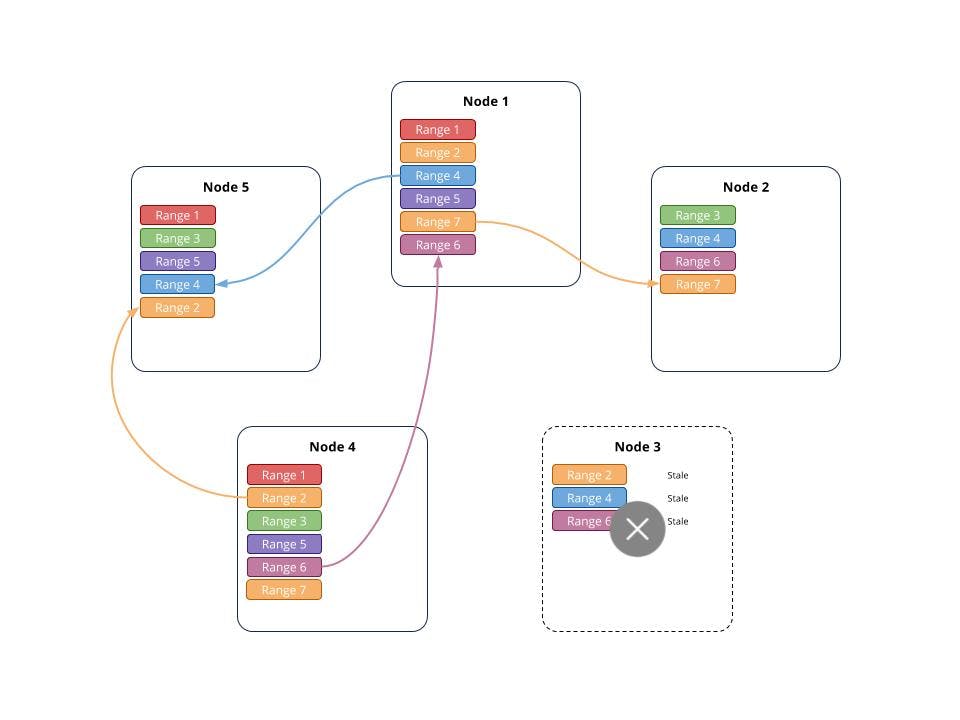
In this figure, Node 3 did not reconnect, so the ranges with missing replicas, 2, 4, 6 and the newly created 7 all add new copies on other nodes.
Automated Rebalancing
One of the most important and novel aspects of CockroachDB is how it continuously rebalances data behind-the-scenes to fully utilize the whole cluster. Let’s start by considering some scenarios that would necessitate rebalancing:
Scenario 1: You’re performing a large number of inserts on a 5-node cluster. The ranges affected are all on 3 of the 5 nodes, and those 3 nodes are starting to fill up while the other 3 nodes are pretty empty.

In this figure, range 4 has grown significantly and has split into ranges 4, 7, 8 and 9. This has created an imbalance such that nodes 1, 2 and 3 now have significantly more replicas than the other nodes. This is remedied by rebalancing. A replica for Range 4 is moved from Node 1 to Node 5. A replica for Range 8 is moved from Node 1 to Node 4. And finally a replica for Range 7 is moved from node 3 to node 5. Now all nodes have either 5 or 6 replicas and the balance has been restored.
Scenario 2: Your entire cluster is getting a little cramped, so you decide to add some new nodes to free up capacity and balance things out.
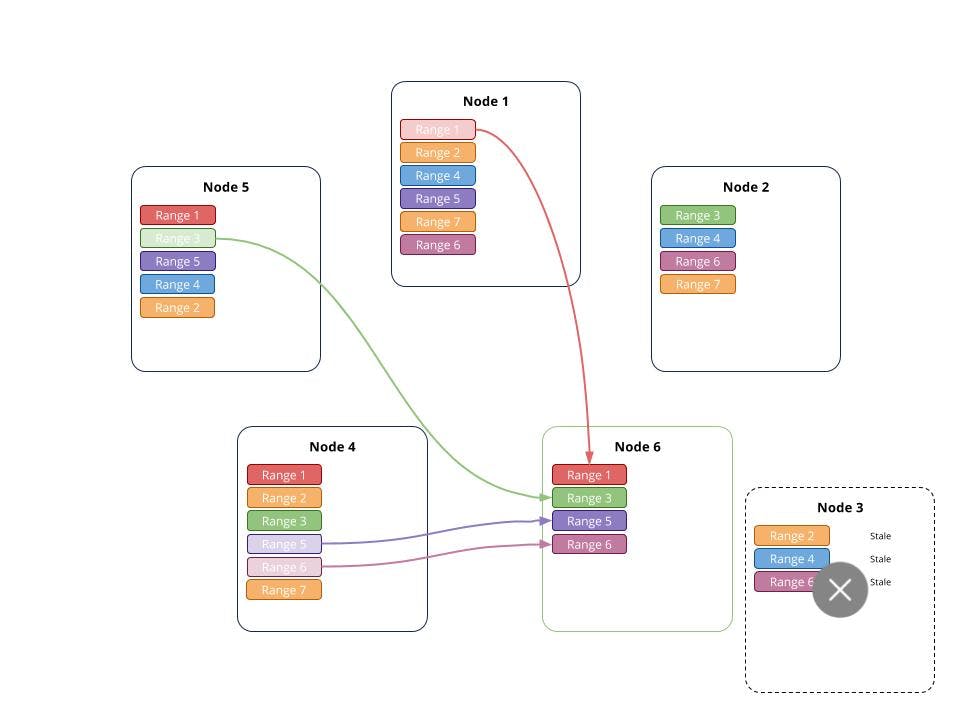
This figure carries on after Node 3 was removed and the cluster repaired itself by making additional copies of the missing replicas. That node was replaced with a new node, Node 6. Once added, there is a clear imbalance. This was remedied by having Node 1 receive a number of replicas. It took a replica for Range 1 from Node 1, a replica for Range 3 from Node 5, and replicas of Ranges 5 and 6 from Node 4. Now all nodes have either 4 of 5 replicas and the cluster is again balanced.
Scenario 3: Availability is important for a specific table that is queried frequently, so you create a table-specific replication zone to replicate the table’s data 5 times (instead of the default 3).
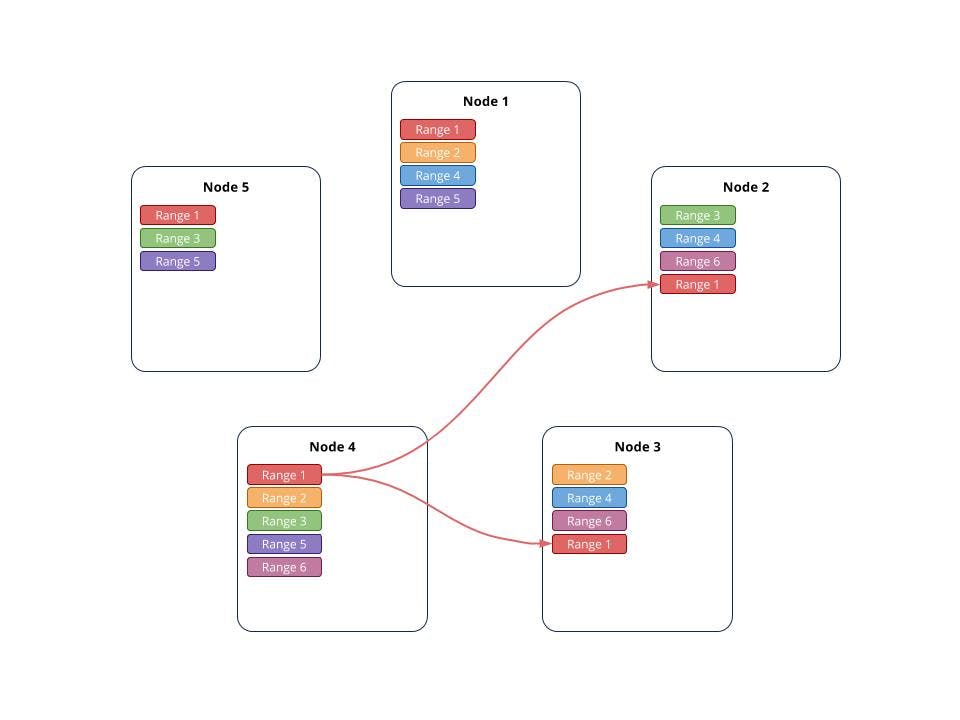
In this figure, Range 1’s replication factor has been increased from 3 to 5. As two new copies are needed, new replicas of range 1 are added to nodes 2 and 5.
In each of these scenarios, there’s a clear need to move replicas around, to less full nodes, to new nodes, or to nodes matching defined constraints. In classic sharded SQL databases, accomplishing this would require manually resharding the whole database, a painful process involving complex application-level logic and plenty of downtime (or at the very least a painful transition) that’s best avoided if possible. In most NoSQL databases, this process usually needs to be carefully planned and scheduled for performance reasons. In contrast, in CockroachDB, the rebalancer is always running and is designed to have minimal impact on performance. There is no need to tune or schedule it, and no need to make your application aware of any changes.
Our Heuristic
So how does CockroachDB decide which nodes should be rebalanced and which nodes are eligible to receive rebalanced ranges? After considering replication zone constraints and data localities, which will be the focus of an upcoming blog post, the primary factor in these decisions is the number of ranges on nodes:
Mean number of ranges in the cluster:
CockroachDB calculates the mean number of ranges across the cluster and considers it the ideal range count for each node. For example, in a five-node cluster, with four nodes containing 20 ranges and the fifth node containing 25 ranges, the mean and ideal count per node would be 21.
Actual number of ranges on each node:
If the number of ranges on a node is above the mean, the node moves enough ranges to other nodes to bring its range count closer to the mean. For example, continuing the scenario above, if 21 were the mean and ideal range count per node, the node with 25 ranges would move 1 range to each of the four other nodes, bringing each node to 21 ranges.
Node storage capacity is also important. Once a node is at 95% capacity, it is no longer considered eligible to receive rebalanced ranges. If any node gets to this state, however, it is a good indication that additional nodes need to be added to the cluster -- a dead simple process. Once nodes have been added, the cluster quickly rebalances as described above. (To see this happen in real-time, try out our getting started tutorial on Scalability.)
Preventing Thundering Herd
When we first implemented rebalancing, adding a new node to a cluster caused a massive rush as all the other nodes immediately tried to move replicas onto it. To prevent this type of “thundering herd” scenario, we implemented a limit on the number of incoming rebalancing requests to a new node. Requests above this limit are rejected, and requesters are forced to either wait or find a different home for the replicas in need of rebalancing.
Preventing Thrashing
Another issue we encountered early on was what we called “thrashing”. Our original heuristic of moving replicas around based just on the mean caused some ranges to keep moving back and forth, ad nauseum. This meant that the cluster would never reach equilibrium such that a lot of replicas were continuously being moved back and forth between nodes. This continuous unneeded movement uses up resources and can add latency to the system. To combat this, a buffer was added to both the high and low sides of the mean (5%). So only once a store was above the mean plus this threshold, was it considered for rebalancing and we only consider a rebalancing if moving a replica actually pushed the cluster as a whole closer to the mean.
Moving a replica
The state of a cluster is always in flux; each node, store and range may be adding and removing data at any time. Replicas are being moved around and repairs may be taking place. In this type of chaotic environment, there is never any point in which any single part will know exactly the full state of the cluster and having a single node act as the coordinator for rebalancing would be both a single point of failure and as the system grew larger, a bottleneck that may slow down rebalancing. Thus the rebalancing problem is solved by allowing each range to determine its own fate by looking at what it thinks the current state of the cluster is.Information about other stores is shared using our gossip network. The details of how that works would be a little be too far afield for this post, but for our purposes, all we need to know is that it spreads the latest replica count, disk sizes, and free space about a store to all other stores in an extremely efficient manner. But this information spreading is not instantaneous and there will sometimes be small difference between these values and the actual ones.In order to perform any repairs or rebalances, each store is continuously looping through all of the replicas that it controls and checks if any of them require repairing (due to not having enough replicas) or rebalancing (when another store is a much more attractive location for one of its replicas).As previously discussed, if there is a need for a repair, it adds a new replica to a store that meets all constraints and has the most free space and removes the reference to the now missing replica. To rebalance the range, it first add the new replica on a new store and then removes the extra replica.
Future work
Clearly the rebalancing and repair mechanism, in its current state, is using only a very limited amount of data to make decisions. There are many promising directions we would like to take this in future releases. Right now, there’s an effort to rebalance based on the actual size of the replicas instead of just their count and to pinpoint hot nodes to spread their replicas around, improving their load and latencies overall. Also, for ranges that are experiencing very high loads, perhaps a way to spread that load around would be to split them, spreading out that load. For more details, take a look at this RFC.
Final Thoughts
These techniques discussed above allow Cockroach to continuously rebalance and spread ranges to fully utilize the whole cluster. By automating rebalancing, CockroachDB is able to eliminate the painful re-sharding procedure that is even still present in most modern NoSQL databases. Furthermore, by automating repairing and self-healing, CockroachDB is able to greatly minimize the number of emergencies due to failing machines. Since this repairing happens without having to schedule any downtime or run specific repair jobs during slow times it is a huge benefit to anyone trying to keep an important database up and serving load.
Our goal from day one has been to Make Data Easy, and we feel that by automating a lot of these tasks, we’ve freed up those who manage databases from the tedium of dealing with these menial and potentially dangerous tasks to instead be able to think about expanding and improving the cluster as a whole.
But there’s much more. We also provide controls, using database and table constraints, which allow you to be a lot more specific about where your data reside and the details of how these function will be covered in an upcoming blog post.
Illustration by Rebekka Dunlap


