

Disclaimer: Data from this blog comes from the State of AI Scale & Resilience Survey, which was conducted by Cockroach Labs and Wakefield Research with 1,125 Senior Cloud Architects, Engineering, & Technology Executives responding, with a minimum seniority of Director in 3 regions across 11 markets: North America (U.S., Canada), EMEA (Germany, Italy, France, UK, Israel), and APAC (India, Australia, Singapore, Japan), between December 5th and December 16th, 2025, using an email invitation and an online survey. Note, results of any sample are subject to sampling variation.

30% of leaders say the database is the first point of failure in AI overload scenarios.
That is not because teams chose the wrong cloud. It is not because they miscalculated capacity. It is because most traditional databases were built for a different era of computing. They were designed around vertical growth, predictable traffic, and human-paced interaction. AI breaks all three assumptions at once.
Models do not sleep. Agents do not queue politely. Traffic does not ramp gradually. It spikes, fans out, retries automatically, and compounds over time. What used to be a rare edge case can become the steady state. The database, once a stable foundation, becomes the first stress fracture, and the last thing you want is a broken system of record.
AI workloads expose the limits of PostgreSQL-era design
PostgreSQL did not fail teams. Teams outgrew what it was built to do.
PostgreSQL excels at single-region deployments with vertical scaling. It is mature, reliable, and deeply familiar to developers and operators. Many AI systems start there. Early pilots run smoothly. Small-scale production environments hold up.
The cracks appear when AI moves from controlled experimentation to real-world scale.
AI workloads introduce sustained machine-generated concurrency. They demand global availability rather than simple replication. They generate constant writes from prompts, responses, embeddings, and feedback loops. Retraining pipelines create additional downstream pressure. Growth compounds rather than stabilizes.
The defining shift is this: AI does not introduce occasional spikes. It normalizes them. Edge cases become the baseline operating condition.
As usage grows, so does coordination overhead. Systems that were manageable under predictable workloads begin to strain under constant contention. Costs rise with concurrency. Operational friction increases with scale. Complexity becomes the tax for staying online.
Why legacy database workarounds stop working
When PostgreSQL reaches its limits, most teams do not rethink architecture. They extend it.
They scale up to larger machines. They separate reads and writes across replicas. They accept asynchronous replication and its tradeoffs. They create increasingly complex multi-tenant schemas. They write custom vacuum jobs, failover scripts, and backup orchestration. They add monitoring layers and, eventually, human oversight during peak hours.
Each decision is rational in isolation. Each buys time.
Collectively, they create a system that is harder to reason about and more fragile under pressure. Operational complexity increases while confidence declines. Engineering time shifts away from product improvement and toward infrastructure stabilization.
That pattern explains why so many leaders now expect database failure before failure in other parts of the stack. AI systems magnify coordination challenges. Legacy active-passive architectures were not designed for sustained global coordination at this scale.
Cisco AI’s breaking point with PostgreSQL
Cisco is a global technology leader building AI infrastructure, secure networking, and software solutions for all. For Cisco’s AI Security team, scaling AI was never about GPUs or models. It was about the database.
The team behind what is now Cisco AI Defense began as Armorblox, an AI-first cybersecurity startup protecting millions of email inboxes from phishing, account takeovers, and business email compromise. Early on, PostgreSQL worked well enough. Like many teams, they paired it with Kubernetes, ran a primary with standbys, and focused on building the product, not database infrastructure.
As customer volume grew into the millions and traffic became increasingly bursty and machine-driven, the database layer became the limiting factor. During peak hours, engineers were waking up everyday at 5am PT ahead of peak traffic just to make sure Postgres stayed online. Time that should have gone into improving AI models and detection logic was instead spent keeping the database alive.
The team did what most organizations do when Postgres starts to strain: They added customizations aka complexity. Then more complexity.
They moved Postgres out of Kubernetes after repeated failovers, resource limits kept getting hit, DevOps complexity, underlying node instability, and noisy-neighbor issues. They removed resource limits from Helm charts, went with multi-zone deployments, introduced maintenance windows for regular upgrades, and implemented huge page tables. Upgrades became extremely complex. The key takeaway was that Postgres was not meant to run in Kubernetes.
So the team switched to running Postgres in VMs and earned some quick wins. They had raised a Series B round of funding and their customer base grew, workloads tripled very quickly. To sustain the growth, they beefed up the node size and increased cluster sizes from 3-nodes to 5-nodes. All reads went to the standby, and the primary was write-only. They began engaging with database experts and consultants as a long-term solution so someone could monitor the database 24/7.
But there were still some additional challenges:
Vertical scaling limits with Postgres
Lack of active-active deployment
Self-imposed problem of multi-tenant schemas, with 10s of thousands of tenants, resulted in over 500,000 large tables
Constantly vacuuming tables with custom vacuum jobs
Issues with backup and restore and replication lags
None of these issues were caused by AI models. They were caused by trying to stretch a vertically scaled, active-passive database architecture into a role it was never designed to play.
The breaking point came when Cisco acquired Armorblox in 2023 and tasked them with building all AI products under the Cisco brand. Thus, AI scale became non-negotiable. At Cisco’s size, “eventually” isn’t good enough. The team needed a database that was:
Truly distributed by design
Minimal operational overhead, easy to scale (managed solution)
Capable of active-active, multi-region operations
Strongly consistent at scale
A solid team of people supporting the database
That search led them to CockroachDB.
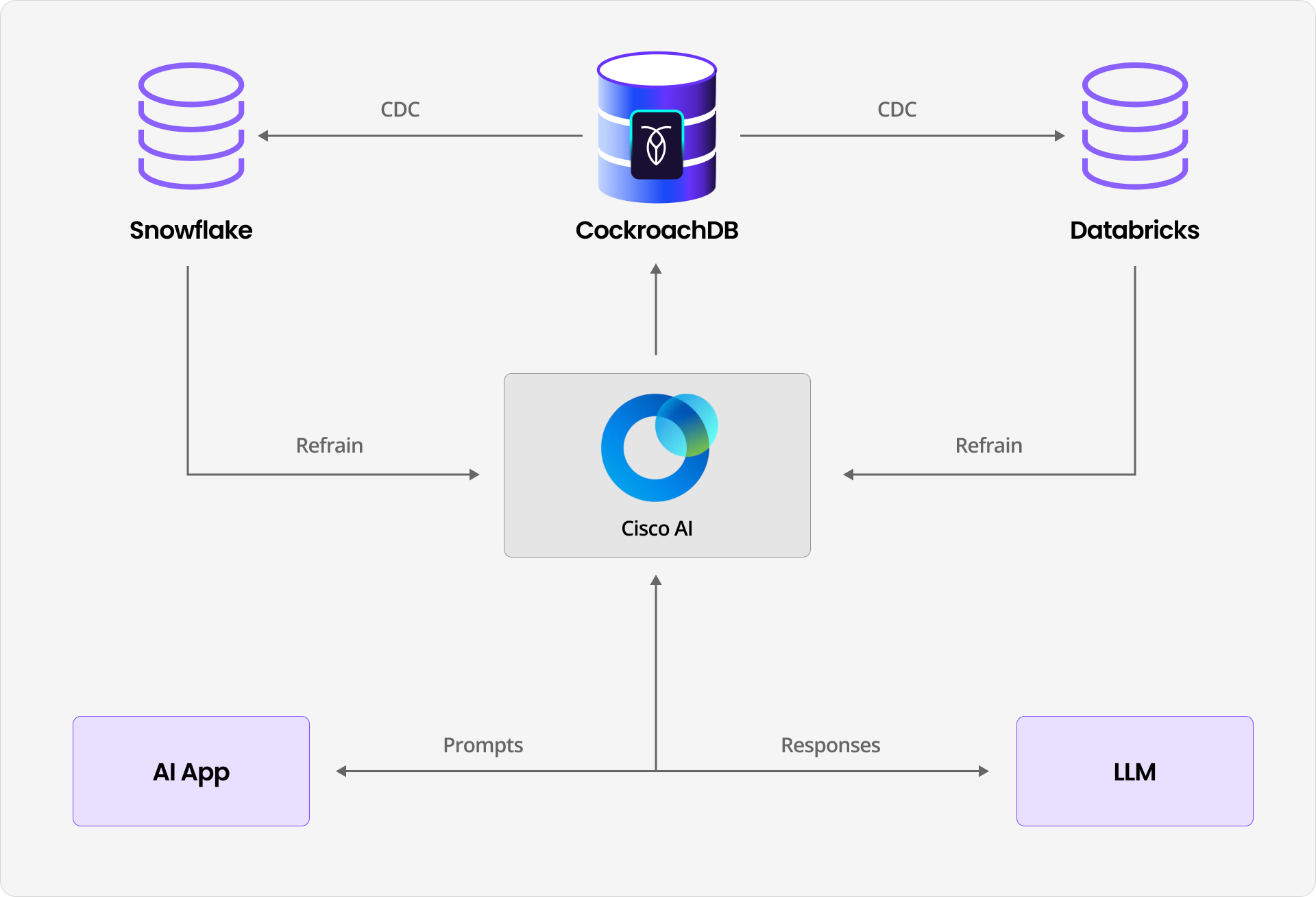
Today, all three major Cisco AI platforms are built natively on top CockroachDB:
Cisco AI Defense: Platform that secures AI apps, agents, MCPs and LLMs
Cisco AI Canva: AI orchestrated generative UI interface that connects into all Cisco products (with a focus on network operations and troubleshooting using AI)
Cisco AI Assistant: Platform for building AI assistants for all Cisco products.
The database stores AI prompts, responses, and full conversational histories across thousands of customers. The deployment spans seven global regions, and feeds downstream ML retraining pipelines via change data capture. Instead of multi-tenant schemas, the team switched to multi-tenant tables. The key outcome: After many years, the team no longer designs their day around database failure modes.
Their takeaway is simple: Postgres didn’t fail them. AI scale exposed its limits.
What breaks first under AI scale
Three constraints consistently surface under AI workloads.
First, vertical scale ceilings eventually impose hard limits. Hardware upgrades buy time, not elasticity.
Second, active-passive architectures introduce fragility. Failovers require coordination. Replication lag creates windows of inconsistency. Under AI workloads, small inconsistencies propagate quickly into downstream systems.
Third, operational overhead expands with concurrency. Vacuuming, monitoring replication lag, managing backups, and coordinating upgrades become ongoing obligations rather than periodic tasks.
For AI teams, this tradeoff is costly. Every hour spent stabilizing infrastructure is an hour not spent improving models or delivering features. In a competitive AI landscape, distraction slows innovation.
What databases must do now
AI workloads redefine baseline expectations for a system of record.
Databases supporting AI platforms must support multi-region active-active writes without manual failover. They must provide strong consistency at global scale. They must scale horizontally by adding nodes rather than rearchitecting applications. They must operate predictably under constant load without requiring manual babysitting. They must also unify transactional and vector workloads within a single system.
These are no longer advanced features. They are structural requirements for AI infrastructure.
When coordination across agents, users, retraining pipelines, and global customers becomes continuous, the database cannot be the weakest link.
Why Cisco AI moved to CockroachDB
Cisco did not switch databases for marginal performance gains. They switched to align their architecture with AI scale.
CockroachDB provided distributed SQL designed for horizontal growth, multi-region active-active deployment, strong consistency without operational tradeoffs, and a managed option backed by enterprise support. It allowed Cisco to consolidate transactional and AI-related workloads while maintaining reliability across regions.
Today, Cisco operates across seven global regions with consistent data and predictable performance. AI conversation histories are reliably stored. Change data capture feeds retraining workflows. Engineering teams focus on advancing AI capabilities rather than managing database incidents.
The database faded into the background, where it belongs.
AI does not wait for infrastructure
AI scale has no patience for bottlenecks at the system of record.
PostgreSQL workarounds can extend lifespan in the short term. They cannot serve as a durable foundation for globally distributed, always-on AI systems.
AI workloads transform coordination into the primary scaling challenge. The database determines whether systems expand confidently or stall under their own complexity.


