
CASE STUDY
Pure Storage uses CockroachDB to retain state and increase fault tolerance
Open source CockroachDB in the Pure Service Orchestrator

Multi-active architecture for high availability
Stateful Kubernetes application
Simplified application code
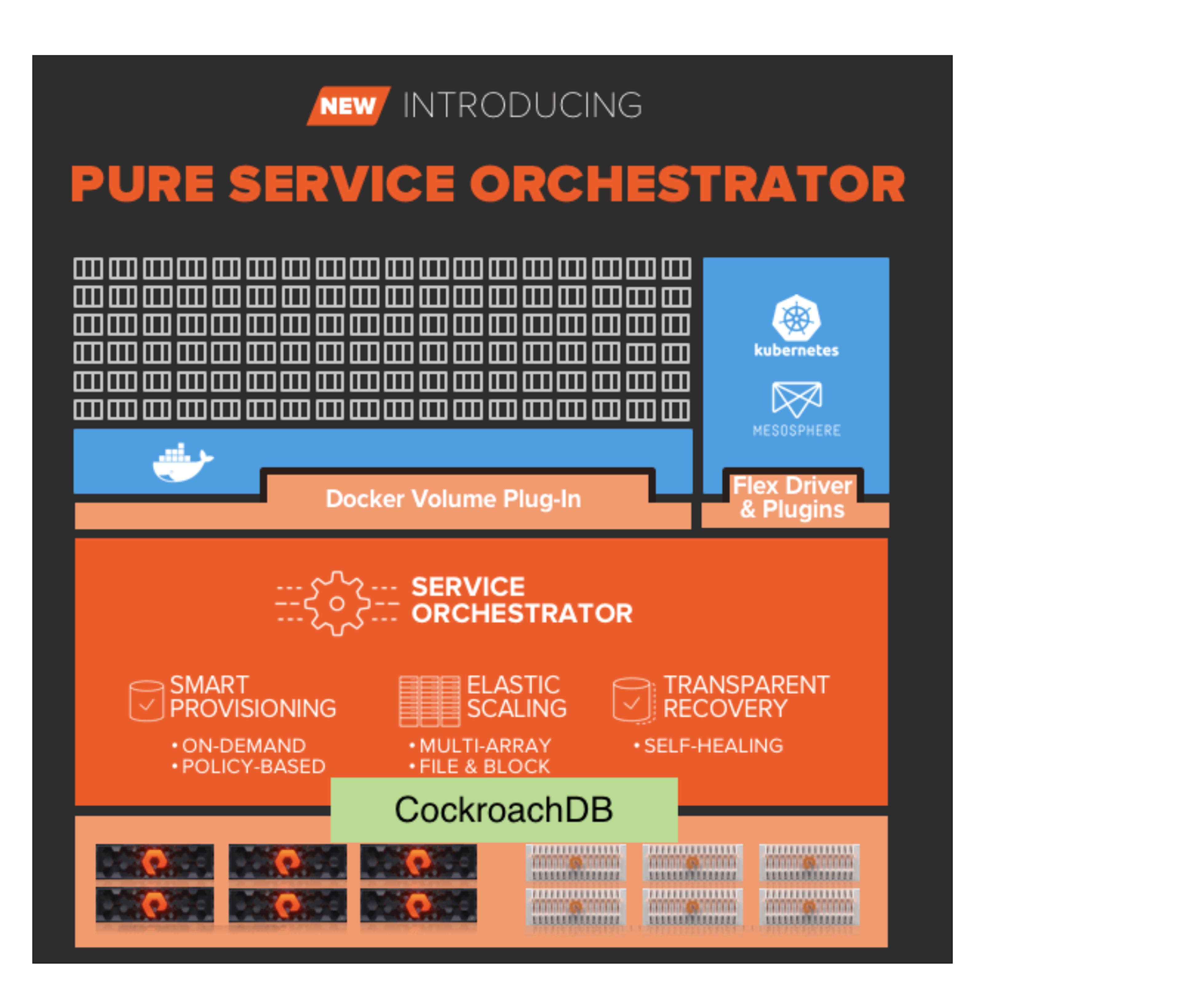
About Pure Service Orchestrator
There is an important architectural change in Pure Storage’s most recent release of their Pure Service Orchestrator TM, a storage-as-a-service product: It’s stateful. All previous versions of the Pure Service Orchestrator were completely stateless. The addition of CockroachDB allows the Pure Service Orchestrator (PSO) to retain state while also making it more fault-tolerant.
In this article we’ll explore the challenges of statelessness, the engineering benefits of statefulness for the Pure Service Orchestrator, why Pure Storage chose CockroachDB (over Postgres, Mongo, Ignite, and Couchbase), and how the Pure Service Orchestrator added CockroachDB to their architecture to retain state.
Retaining State
Stateless Versions of the Pure Service Orchestrator
For years the Pure Service Orchestrator (PSO) has been delivering storage-as-a-service for cloud-native applications by abstracting storage across multiple classes of on-prem and cloud storage.
Version PSO5 and below were all stateless storage plugins. They did all their work based on Kubernetes objects and the names of volumes on the backend. The advantage of doing things this way was that if one of the plugin pods crashed, PSO had all the names of the volumes on the backend, which allowed them to just pick back up where they started. It also allowed them to avoid the need for a central data store to hold state, which could introduce a single point of failure.
Too Many REST Requests
Statelessness started to become a problem because PSO engineers had to make a lot of REST requests to get info from the backend. This made it difficult for them to be productive. When PSO needed to recreate the current state, it executed list operations, which needed to be executed by each stateless part of PSO. The overhead of this task grew in proportion to the size of the deployment.
No Stateful Backend Storage
Sometimes there was metadata they wanted to store but couldn’t store in the storage backend so they needed to add a database to store it. To solve this they tried to use ETCD in some of the early cases. The problem is that ETCD is part of Kubernetes, and so it was too coupled to the Kubernetes installation. So, if they had to tear down the Kubernetes cluster and build a new one, how would they move data out of ETCD? Having a separate data store solves this.
By adding CockroachDB as a storage backend for metadata they been able to store debugging information in the database, like general progress states such as, ‘how far did we get in provisioning this volume before it failed?’, ‘is this attachment attaching, attached, detaching, or detached…’.
Working Around Statelessness
The engineering team architected around the statelessness in PSO 5.0 and below by doing a thing called a Volume Import. In Kubernetes you can do a persistent volume claim, which is how you provision storage, and you make a new volume.
If a customer has pre-Kubernetes data that they want to move over, then they use the Volume Import. This worked before Pure Storage created FlashBlade (a storage solution for unstructured data). Because FlashBlade is NFS-based, it broke the stateless approach PSO 5.0 was using before. This became a painful workaround. And was one of the moments in which PSO engineers decided that having state would make their work easier.
Pure Service Orchestrator Requirements for a Stateful Database
1. The database must be strongly consistent: Because if you add a new storage volume, and then try to use it, but the container can’t see it - that would be a problem. Any “eventually consistent” data store would have this problem. But a strongly-consistent data store would not have this problem. If you add records about a volume, the next operation would see that data correctly.
2. The database must be transactional: If you delete a volume, you don’t want to see it in the next operation where you list the existing volumes. That would confuse users.
3. The database must be relational: PSO’s data model is naturally relational. So trying to shoehorn that data model into a non-relational database would make the application too complicated.
Why Pure Storage Chose CockroachDB
As mentioned briefly above, the PSO team initially considered ETCD before eliminating it because it’s coupled with Kubernetes. Next, PSO considered Postgres, MongoDB, Couchbase, and Apache Ignite.
Postgres - eliminated for being difficult to scale, and to keep up and running (especially automatically).
MongoDB - eliminated because there would have been problems with the transactional requirements of their data model (yes, they could have made NoSQL work, but it isn’t super clean).
Couchbase - Too complicated to use sync gateway for getting notifications Apache Ignite - Too much complexity to use separate disk drives for write-ahead logs and database files for better performance.
Pure Storage found CockroachDB through the CNCF and noted that it met each of their fundamental database requirements (consistent, transactional, relational). And it performed well on their initial performance tests. Above all else, CockroachDB was architecturally a better fit for the Pure Service Orchestrator because of its multi-active availability.
The Primary-Secondary architecture of MySQL, Postgres, and other databases can get up and running in Kubernetes, but when there’s a failure it’s complicated to have it all reconcile itself, with zero data loss, in an automated fashion. These databases use Primary-Secondary architecture to deliver high availability. This means that if the Primary dies (or if Kubernetes moves it) the Secondary has to be activated and applications need to be rerouted to the Secondary. Then, to bring the Primary back up, someone or something has to recreate the Primary (in most cases). It’s a lot of work because it was designed as a solution for keeping data during a disaster. It was not designed for keeping containers available in a constantly changing Kubernetes environment.
With CockroachDB you have 5-7 pods and if Kubernetes starts moving pods around, the database stays up, and Pure Service Orchestrator can still access the database despite the movement.
The Data Stored by CockroachDB in the Pure Service Orchestrator
In the Pure Service Orchestrator architecture, CockroachDB is responsible for storing metadata. PSO has a few main objects that they work within Kubernetes: The volumes and snapshots of volumes - that’s a relationship they need to maintain. They have attachments, which is when a volume is mounted onto a node, and that has a column reference inside of it. PSO needs to query between attachments and volumes. Those attachments are also on a node, so they need some node metadata. Also, they mount from a backend so they need backend metadata. All of those are linked.
All of which is to say: the data is very relational, so it’s important to have a relational database.
The Pure Service Orchestrator Architecture
The Cockroach operator that PSO built bootstraps the database on their own storage. No additional storage is required to manage the database. PSO 6.0 uses the same FlashArray and FlashBlade systems they use for user provisioned storage and the operator manages scaling and replicating between all of them.
For example, when a customer has some FlashBlade storage and some FlashArray storage the operator will spread out CockroachDB’s data across both. In other words, customers do not have to configure storage just for CockroachDB, because it’s taking a little slice of their existing storage.
The operator handles not only pod availability, but also storage availability. If storage goes offline, customers can still see information about that storage in PSO 6.0 because that information is stored in CockroachDB which has nodes spread across all of the different storage devices.
PSO 6.0 has several backends, including FlashArray and Flashblade. With CockroachDB they scale out and scale in to distribute replicas across different backends to provide high availability (without introducing a single point of failure). If more FlashArrays are added, then PSO 6.0 can spread CockroachDB data across that extra storage to take advantage of the higher redundancy available.
Benefits of CockroachDB
CockroachDB Gives Pure Storage Better Reliability
Because PSO 6.0 is storing metadata in CockroachDB (which is resilient to server and storage failures) PSO 6.0 can provide customers with information and management of storage even if that storage is offline.
CockroachDB Unlocked a Communication Use Case
As part of the PSO plugin there are two main things that need to run: the Controller pod and node pods. Previously these pods could not talk to each other. But now they can use CockroachDB as a pseudo-communication layer. This enabled a new feature they call “Controller Attach/Detach” which is where they only need credentials for the controller pod and the node ones don’t need it, which increases security.
CockroachDB Simplifies Application Code
In CockroachDB it’s very easy to decommission, recommission, add, and remove nodes. This makes the PSO 6.0 application code cleaner and less prone to bugs. It also allows the engineering team to innovate and improve the PSO faster because they don’t have to maintain an excess of code to handle Primary/Secondary failovers.
CockroachDB Behaves as a Cache Layer
This is important because when the scale goes up, the volumes and snapshots go up, and the operational overhead increases. PSO uses a lot of lists and the API calls get expensive.
Having CockroachDB in the middle makes it easier. Each part of PSO5 had to list everything for itself, which was slow when scale went up. But with CockroachDB, one service can list, store the list in the database, and then all the other services can read the list in CockroachDB. This is much faster and requires less REST calls to the storage.
The Future of the Pure Service Orchestrator and CockroachDB
With CockroachDB, the Pure Service Orchestrator is able to ensure that their customers always have access to their data by moving to a stateful model. This improved the ease of use for end-users, enhanced the performance of PSO, and helped simplify PSO 6.0 to allow faster innovation, and richer features in future versions. The PSO engineering team is excited to see the impact of keeping data about all the volumes in CockroachDB. In particular they’re eager to see how CockroachDB lets them relationally query information to derive insights that weren’t available when PSO was stateless. They expect statefulness to open up new use cases in the PSO Explorer which could, for example, leverage database information to search for new insights in the data that’s already present in the database.
Pure Storage evaluated other databases for this project, but discovered that CockroachDB was the most seamless fit because of its multi-active availability, strong consistency, ACID transactions, and Kubernetes compatibility. With CockroachDB, PSO 6.0 is more resilient and has built a foundation on which to strengthen its position as the premier storage-as-a-service vendor.
