Dashboard navigation
Use the Graph menu to display metrics for your entire cluster or for a specific node. To the right of the Graph and Dashboard menus, a time interval selector allows you to filter the view for a predefined or custom time interval. Use the navigation buttons to move to the previous, next, or current time interval. When you select a time interval, the same interval is selected in the pages. However, if you select 10 or 30 minutes, the interval defaults to 1 hour in SQL Activity pages. When viewing graphs, a tooltip will appear at your mouse cursor providing further insight into the data under the mouse cursor. Click anywhere within the graph to pin the tooltip in place, decoupling the tooltip from your mouse movements. Click anywhere within the graph to cause the tooltip to follow your mouse once more. The Changefeeds dashboard displays the following time series graphs:Max Changefeed Latency
This graph shows the maximum latency for resolved timestamps of any running changefeed.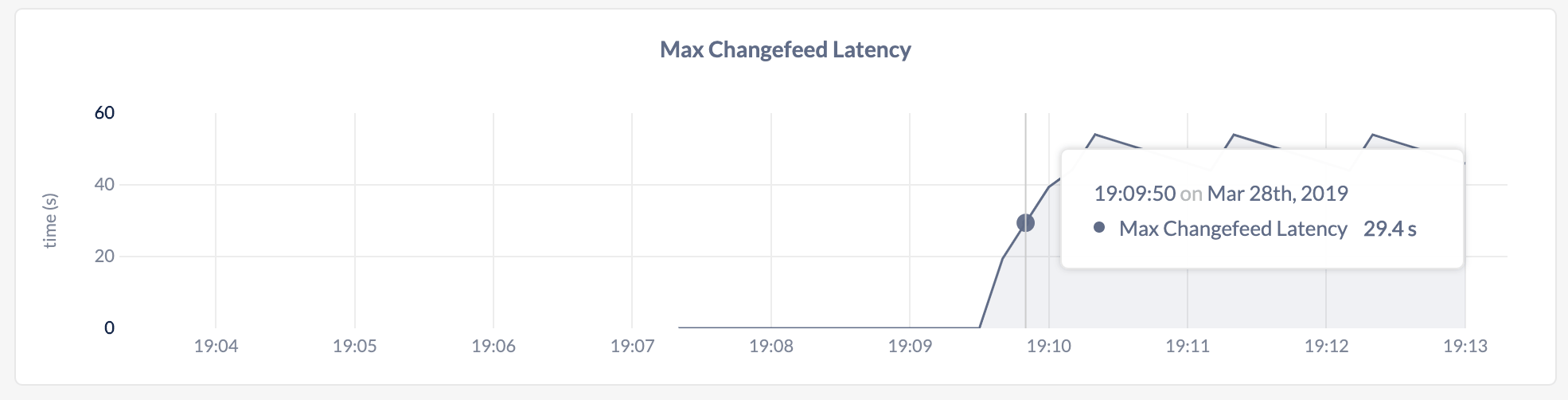
The maximum latency for resolved timestamps is distinct from and slower than the commit-to-emit latency for individual change messages. For more information about resolved timestamps, see .
Sink Byte Traffic
This graph shows the number of bytes emitted by CockroachDB into the sink for changefeeds.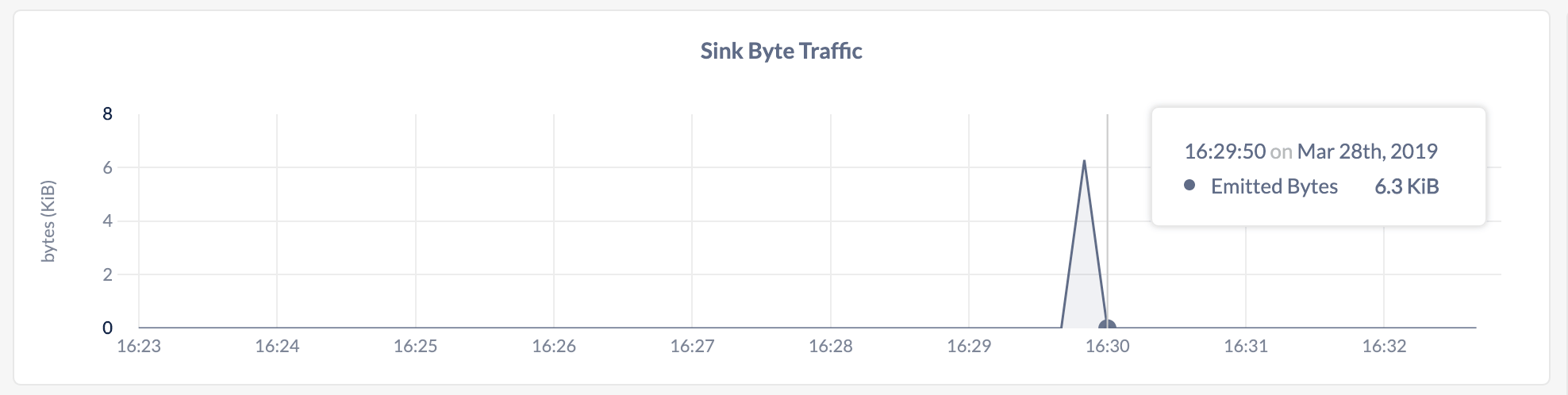
Sink Counts
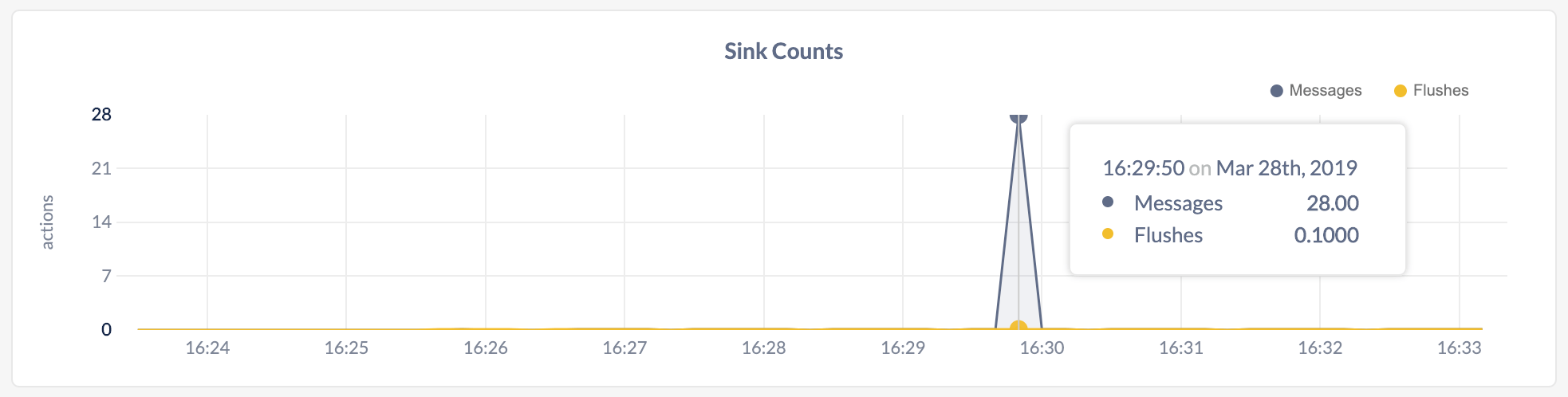
This graph shows:- The number of messages that CockroachDB sent to the sink.
- The number of flushes that the sink performed for changefeeds.
Sink Timings
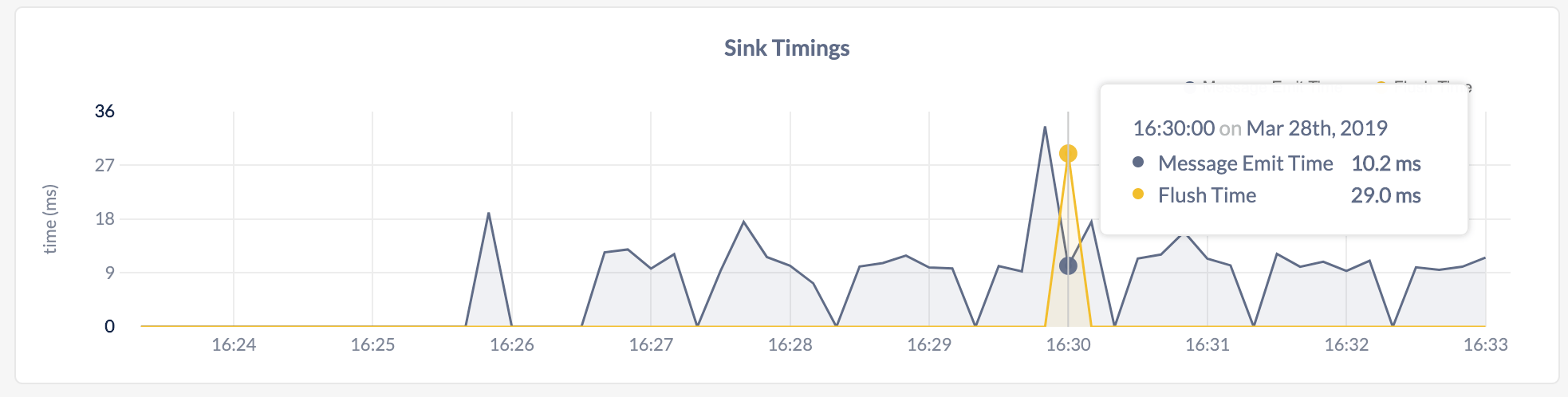
This graph shows:- The time in milliseconds per second required by CockroachDB to send messages to the sink.
- The time CockroachDB spent waiting for the sink to flush the messages for changefeeds.
Changefeed Restarts
This graph displays the number of times changefeeds restarted due to retryable errors.
Summary and events
Summary panel
A Summary panel of key metrics is displayed to the right of the timeseries graphs.
If you are testing your deployment locally with multiple CockroachDB nodes running on a single machine (this is ), you must explicitly per node in order to display the correct capacity. Otherwise, the machine’s actual disk capacity will be counted as a separate store for each node, thus inflating the computed capacity.
Events panel
Underneath the Summary panel, the Events panel lists the 5 most recent events logged for all nodes across the cluster. To list all events, click View all events.
- Database created
- Database dropped
- Table created
- Table dropped
- Table altered
- Index created
- Index dropped
- View created
- View dropped
- Schema change reversed
- Schema change finished
- Node joined
- Node decommissioned
- Node restarted
- Cluster setting changed